Fuzzware: Using Precise MMIO Modeling for Effective Firmware Fuzzing
论文动机
在资源受限的嵌入式设备上fuzzing固件效率很低,当前最先进的方法是在模拟器中重新托管固件(re-hosting)。但是目前的re-hosting建模方式存在一些问题:
- 硬件行为的粗粒度静态建模 —— 对硬件行为的模拟不够精确
- 手工重新托管固件 —— 大量人工参与,不够自动化
论文基于这样一种认识:固件对于外设的访问往往是瞬间的短期的,并且发生这种访问的原因与固件的整体行为无关,例如去检查外设的状态或对外设进行配置。这时,并不是固件获取到的输入序列中的所有数据位都有价值,例如,固件可能会直接从一个32位输入序列中提取某些位作为有效数据或根据输入序列中的几个比特来辨别外设的状态。这说明固件在访问外围设备时将会产生很大的输入开销。
基于这种认识,论文尝试对于硬件的MMIO行为进行精确建模。
前序工作
与本篇文章联系紧密的两个前序固件仿真工作:
- P2IM(2020):主要针对寄存器行为模式进行建模
- µEmu(2021):基于引导符号执行对外设行为建模
主要贡献
- 提出了一种细粒度的MMIO访问建模方法。这种方法经过优化,可与基于覆盖率引导的模糊器一起使用进行漏洞挖掘。
- 能够识别比特级别的硬件行为 —— 对比P2IM(寄存器级别的行为)
- 保留了固件逻辑的所有路径,没有进行路径消除
- 使用局部范围的动态符号执行来分析硬件生成值的哪些部分实际上对于固件逻辑有意义
- 实现了一个高效、自适应的模糊测试系统Fuzzware
- 优于之前的工作(主要指µEmu 和P2IM)—— 通用性、代码覆盖率大幅度提升
背景知识
驱动与设备通信
-
MMIO (Memory-mapped I/O)
- 普通内存(RAM)和外设I/O使用相同的地址空间(统一编址)
- 外设I/O和内存I/O使用相同的指令
-
PMIO (Port-mapped I/O)
- 内存和I/O设备有各自的地址空间
- 端口映射I/O通常使用一种特殊的CPU指令,专门执行I/O操作
-
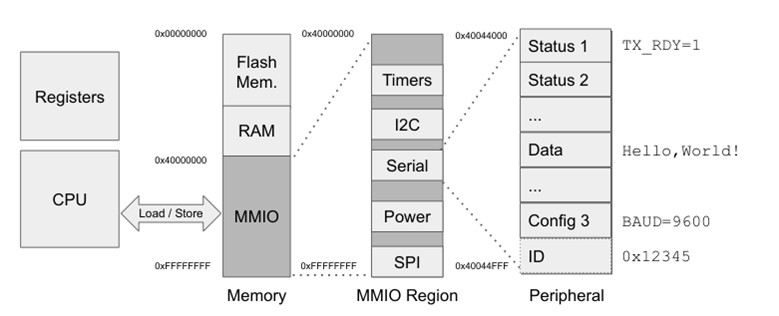
通信示例:
考虑在以下带有串行端口的单片机上使用MMIO与外设进行数据交换:
- 固件通过检查MMIO区域内外设状态寄存器所在的地址来判断是否有数据传入
- 当检测到有数据要传入时,固件将从MMIO区域中外设的数据寄存器的地址中读取到串行数据
硬件Re-hosting
-
概念:Rehosting译为重托管,可以简单理解为Re+Host,通过将所需的固件模块在新的宿主(host)上运行,以达到大规模的低成本动态分析和安全研究目的
-
目标:通用、自动化固件仿真
-
一般来说,重新托管嵌入式固件需要模拟三种交互:
-
MMIO —— 使用最频繁
MMIO是嵌入式固件与硬件交互过程中使用最为频繁的,针对MMIO的仿真和建模是固件能够成功rehosting的关键,也是本文工作的焦点。
-
中断
-
DMA —— 最难仿真
DMA在交互过程中不经常使用并且非常难以自动建模,因为它的 I/O 行为严重依赖于单个外设的内部设计,并且嵌入式外设往往倾向于与固件交换少量的数据。
-
-
两种MMIO托管的思路
- 精确模拟MMIO行为: 完全实现每个MMIO寄存器的行为
- 这种方式需要访问完整的硬件文档并进行大量工程设计
- 近似模拟MMIO行为:主要使用模糊测试的方式,让模糊器来提供MMIO的输入
- 允许没有任何的先验知识的情况下运行固件
- 要面对庞大的搜索空间:对于一个32位的MMIO寄存器值,在不加引导的情况下,要在2的32次方个候选值中进行搜索,产生很大的开销
- 模糊器产生的一些可用输入无法对应到实际的硬件MMIO输入
- 精确模拟MMIO行为: 完全实现每个MMIO寄存器的行为
模糊器MMIO输入的组成
-
Fuzzer产生的MMIO输入的组成:
-
相关比特位:这些数据位将实际影响固件逻辑处理
- 例如通过检查sr的置位来判断是否有数据到达
- 对于模糊器来说是有效的比特位
-
输入开销:对固件逻辑的执行没有影响,但是出于硬件结构考虑必须要提供的数据位。 注意输入开销是针对模糊器而言的
-
完全输入开销 (Full input overhead):获取到的MMIO输入序列对于固件逻辑没有影响
fuzzer提供的所有bit都不影响固件逻辑,整个产生的输入序列都属于输入开销
-
部分输入开销 (Partial input overhead):获取到的MMIO输入中部分位对于固件逻辑没有影响
例如访问一个32位的MMIO寄存器,实机上只使用了返回输入序列中的8位,那么模糊器就会引入24位的部分输入开销。
-
-
MMIO建模方法
-
高级仿真:通过hook和重新部署函数库的方式来避免外设逻辑和MMIO访问,高级仿真不需要对特定的硬件外设进行建模,但是手动工作量较大
-
基于模式的MMIO建模 —— P2IM:
方式:
- 使用基于寄存器访问模式的启发式方法减少输入开销
- 基于对MMIO寄存器的使用经验设计预定义模式
- 这种方式将监控MMIO寄存器的行为并将其与预设的模式匹配,之后由模型来决定以怎样的方式给固件提供MMIO输入
-
基于引导符号执行的建模 —— µEmu :
- 改进了基于模式的 MMIO 建模, 与启发式分配静态模式不同,对硬件的访问被视为符号值, 每当需要一个 MMIO 访问的具体值时,符号执行就会朝着最有希望(固件逻辑的覆盖率更高)的路径求解底层符号变量。
研究问题
目前的MMIO建模方案主要存在以下的问题:
- 针对每个固件的手工工作
- 不完全的输入开销消除
- 路径消除
针对固件的手工工作
- 高级仿真:需要通过大量hook和重新部署函数库
- 基于模式的MMIO建模:需要更正错误分类的MMIO寄存器
- 基于引导符号执行的建模:识别符号执行的活动点和终止点
不完全的输入开销消除
- 粗粒度的MMIO建模:寄存器级别的建模(P2IM)
- 影响:缺乏对于固件内部逻辑的洞察力,不能消除部分开销,模糊器将花费大量时间来改变对程序逻辑没有影响的值
路径消除
- 路径消除:基于引导的符号执行使用启发式和人工协助来决定哪些路径值得探索,在选择的同时也丢弃了一些路径
- 影响:
- 遗漏一些固件功能:在执行过程中消除了一些可用的执行路径,导致一些固件功能无法被分析到
- 忽略了错误处理和恢复程序:在正确建模的情况下,固件不会执行到错误处理和恢复逻辑,但是这些功能也可能包含漏洞
系统设计
观点
- 必须避免路径消除:提高代码覆盖率,进行更加广泛的fuzz
- 尽可能地消除输入开销:缩小模糊器的搜索空间,进行更加有效的fuzz
- 提高自动化程度:减少不必要的手动工作
威胁模型
- 可用资源
- 目标设备的二进制固件映像
- 基本的内存映射(例如内存范围、外设到MMIO区域的映射关系等)
- 威胁模型
- 攻击者没有关于给定固件硬件环境的额外知识
- 攻击者能够控制提供给固件的输入:
- 通过MMIO读取到的网络数据包
- 通过串行接口接收到的数据
- 温度测量之类的传感数据
- … …
整体架构
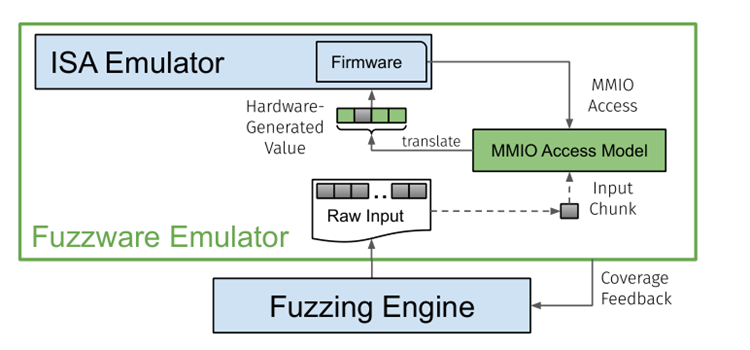
Fuzzware的主要组成部分:
- ISA仿真器:主要负责执行固件代码中与外设行为无关的部分
- 覆盖率引导的fuzz引擎:负责给MMIO访问模型提供原始输入
- MMIO访问模型:作为fuzz引擎和固件之间的代理,将模糊器提供的原始输入处理成能够被固件使用的硬件输入
Fuzz流程
Fuzzware的一个仿真周期
- 将固件映像加载到ISA仿真器中开始仿真
- 使用harness工具动态拦截所有MMIO访问
- 当harness工具拦截到一次MMIO访问时,将检查是否为该访问分配了模型:
- 如果分配了模型:
- 对于完全输入开销,harness可以在不消耗fuzzer提供的原始输入就能进行处理
- 对于部分输入开销,harness将只消耗所需要比特的模糊输入
- 如果没分配模型:直接消耗fuzzer提供的原始输入作为MMIO输入
- 如果分配了模型:
- 当模糊器提供的原始输入消耗完时,模拟器将停止运行固件代码,一个周期结束
- 一个仿真周期结束后:
- harness 将固件恢复到初始状态
- harness 将仿真代码的覆盖反馈给模糊引擎
- 模糊引擎基于反馈生成新的原始输入并提供给harness以供下一个仿真周期使用
MMIO建模过程
- 建模时机:Fuzzware为每个新的可见MMIO上下文进行建模
- 如何鉴别一个新的MMIO上下文:使用**(程序计数器,MMIO地址) **的值对就能够唯一的标识一个MMIO访问
- MMIO建模过程
- 在固件进行新的MMIO访问之前创建固件状态快照(包括寄存器和内存)
- 将快照传递给动态符号执行(DSE)引擎进行建模
- DSE从固件状态快照处开始符号执行代码
- 符号执行期间观察到的每个MMIO访问都是一个单独的符号变量
- 根据符号执行的终止状态判断应该给该MMIO访问分配什么样的模型
-
DSE过程的终止条件
-
所有被跟踪的符号变量都不再活跃(dead)
-
当前函数返回
-
追踪的符号变量离开分析范围
-
到达预定义的资源限制:执行时间、符号状态数、DES的步数
基于这样的考虑:MMIO 寄存器状态具有短暂性。达到终止条件的符号状态将用作输入分析和配置MMIO访问模型
-
模型定义

Hamming weight (HW):是相对于全零位串的汉明距离,在最常见的数据位符号串中就代表1的个数
-
常量模型(Constant Model):将特定常量作为比较条件,只有满足该条件才能继续执行。
- 常量作为比较条件,输入值必须等于常量才能够继续执行
- 模型输入:常数值
- 模型输出:常数值
- 输入开销:全部输入开销
- 消耗模糊输入:0
模糊器不需要提供数据,由模拟器提供常量数据来保证代码能够继续执行,消除了完全输入开销

-
直通模型(Passthrough Model):提供给固件的硬件生成值不会影响固件执行状态,这种MMIO访问被视为常规内存访问(例如对于配置寄存器的访问)
- MMIO输入不会影响固件执行,被视为常规内存访问
- 模型输入:无
- 模型输出:已存储的值
- 输入开销:全部输入开销
- 消耗模糊输入:0
模糊器不需要提供数据,因为硬件提供的值对于固件状态没有影响,这种MMIO访问将被视为常规内存访问,消除了完全输入开销

-
位提取模型(Bitextract Model):在这种模型中,固件只使用了MMIO读取到的数据的部分位(需要掩码的场合:保留特定位、移位、截断、equivalent instruction composites)
- MMIO输入的部分位将影响固件逻辑的执行
- 模型输入:掩码
- 模型输出:模糊输入 + 比特掩码
- 输入开销:部分输入开销
- 消耗模糊输入:HW(掩码) —— 掩码的汉明重量(Hamming weight
模糊器提供需要的位(例如被掩码保留的有效位),模拟器拿到这个值拼接生成完整的输入,消除了模糊器的部分输入开销


-
集合模型(Set Model):当需要通过根据硬件提供的不同的值(这些值都是预先可知的)来确定控制流的执行情况时(每个不同的值将对应一个控制流选项),这时可以通过编码的形式提供这些值,例如当有四个确定值选项时,只需要使用2bit的编码就可以描述所有情况。
- 固件根据一组常量值来确定执行流的走向
- 模型输入:常量集合
- 模型输出:常量集合中的某个值
- 输入开销:部分输入开销
- 消耗模糊输入:log2 (常量集合大小)
模糊器提供一个编码值,模型根据编码值生成正确的硬件需要的值(例如2bit的0x01就代表第2种硬件值)

-
身份模型(Identity Model):在DSE确定硬件生成值的所有位都对挂件状态有影响时会采用这种模型
- 硬件生成值的所有位都有意义、超过DSE资源限制、符号变量超出分析范围等
- 模型输入:无
- 模型输出:模糊器提供的值原封不动的输出
- 输入开销:无
- 消耗模糊输入:整个MMIO访问需要的数据大小
中断、计时器和DMA建模
- 中断:ISA模拟器不能处理中断,因此中断需要由fuzzware来触发。fuzzware在执行了一定数量的基本块(basic blocks),以滚动的方式来触发当前启用的中断。
- 计时器:fuzzware允许精确控制在什么时间点触发哪些中断。模糊器的输入可以用来决定下一个中断的时间以及它的数量,这可以帮助模糊器来探测特定的中断时序对于固件行为的影响。
- DMA:fuzzware可以通过将数据传输缓冲区定义为MMIO来支持某些形式的DMA,但是fuzzware并没有以自动化的方式显式的对DMA进行建模。
系统实现
-
ISA仿真器
- 使用Unicorn Engine作为Fuzzware的ISA模拟器
- 使用原生 Unicorn API 为 MMIO 区域注册内存访问挂钩来处理 MMIO 访问
- 在执行MMIO读取之前会将分配模型的输出写到MMIO区域中
- 使用(程序计数器,MMIO地址)来标识关联模型,MMIO访问没有关联模型时,默认使用身份模型
-
模糊引擎
- 使用AFL作为模糊引擎,方便与其他建模工作做对比
- 使用三个通用文件作为初始fuzzing输入
- 全0位 all zero-bits
- 全1位 all one-bits
- 串联的32位值,每个值都有一个移位 concatenated 32-bit values with a shifting 1-bit each
- 在字节粒度上使用原始输入
- 原因:根据经验,在比特粒度上使用未修改的模糊器提供的原始模糊输入将会影响模糊器输入突变的过程,因此fuzzware选择在字节粒度上使用原始输入(raw input)
- 结果:这样做的结果是虽然每次访问具有四个元素的集合模型需要两位模糊输入,但在当前的实现中还是消耗了一个字节。
-
定时器和中断
- 通过模拟基本块的数量来测量经过的时间
- 扩展了 Unicorn 引擎,实现了 Cortex-M 标准中定义的中断控制器 (NVIC) 和系统节拍定时器 (SysTick)
-
动态符号执行引擎
-
使用angr作为Fuzzware的DSE引擎 —— 支持广泛的架构
-
使用引用计数来跟踪符号变量的活跃度
-
当包含被跟踪变量的符号表达式被写入寄存器或内存时,增加变量的引用计数
-
当这样的符号表达式被重写时,就会减少引用计数
-
-
在达到DSE的退出条件时,通过检查实时的符号表达式和结果状态的约束可以实现对MMIO模型的分配
-
-
MMIO模型分配
- 常量模型分配
- 所有的符号变量都不再被引用
- 结果状态:只有最后一次分配的变量值v满足状态约束
- 实例化模型参数:常数值
- 直通模型分配
- 所有的符号变量都不再被引用
- 结果状态:不约束结果状态
- 实例化模型参数:无
- 位提取模型分配
- 对符号变量引用位掩码后,所有状态约束和符号表达式保持不变
- 实例化模型参数:位掩码
- 集合模型分配
- 所有符号变量不再被引用
- 结果状态:对于每个状态和引用计数变量,可以找到至少一个不满足其他状态路径约束的值
- 实例化模型参数:每个集合分区的最小代表
- 身份模型分配的情况
- 以上模型均不适用
- 在DSE的范围限制内没有找到合适的模型
- 实例化模型参数:无
- 多个模型分配的情况
- 如果出现了匹配多个模型的情况,将选择输入开销减少最多的
- DSE资源限制条件:每个模型匹配过程最长5分钟,最多执行1000个符号执行的基本块
- 常量模型分配
系统评估
-
用来评价FUZZWARE的RQ(research question):
- 实现基于符号执行的建模将引入多大的计算成本?
- fuzzware将因为其保守的建模分析范围而错过多少优化建模的机会?
- fuzzware的MMIO访问模型的通用性如何,是否适用于各种固件和不同的硬件平台?
- 与之前的方法相比,fuzzware对于单片机固件的fizz效果如何?
- fuzzware可以用于发现实际固件中未被发现的漏洞或bug吗?
-
对RQ1,2,3做出的一些评估
-
最初的评估测试:
- 硬件平台多样性:为ARM的Mbed系统支持的十个硬件平台生成了固件映像,来测试同一个应用程序,这样做的目的是为了测试fuzzware在MMIO建模上的通用性。
- 应用层软件多样性:在P2IM的作者最初发布的66个单元测试上测试了fuzzware
-
测试程序的执行流程:
- 程序通过调用Mbed OS提供的高级API来反复触发特定硬件平台的驱动程序行为,这将会进一步被解析为特定于平台的驱动程序函数从而触发MMIO访问过程。
- 之后,测试程序将会通过串行端口提示用户输入密码。如果输入了正确的密码,固件将会暴露一个函数,这个函数从串行端口接收输入并且容易受到攻击。
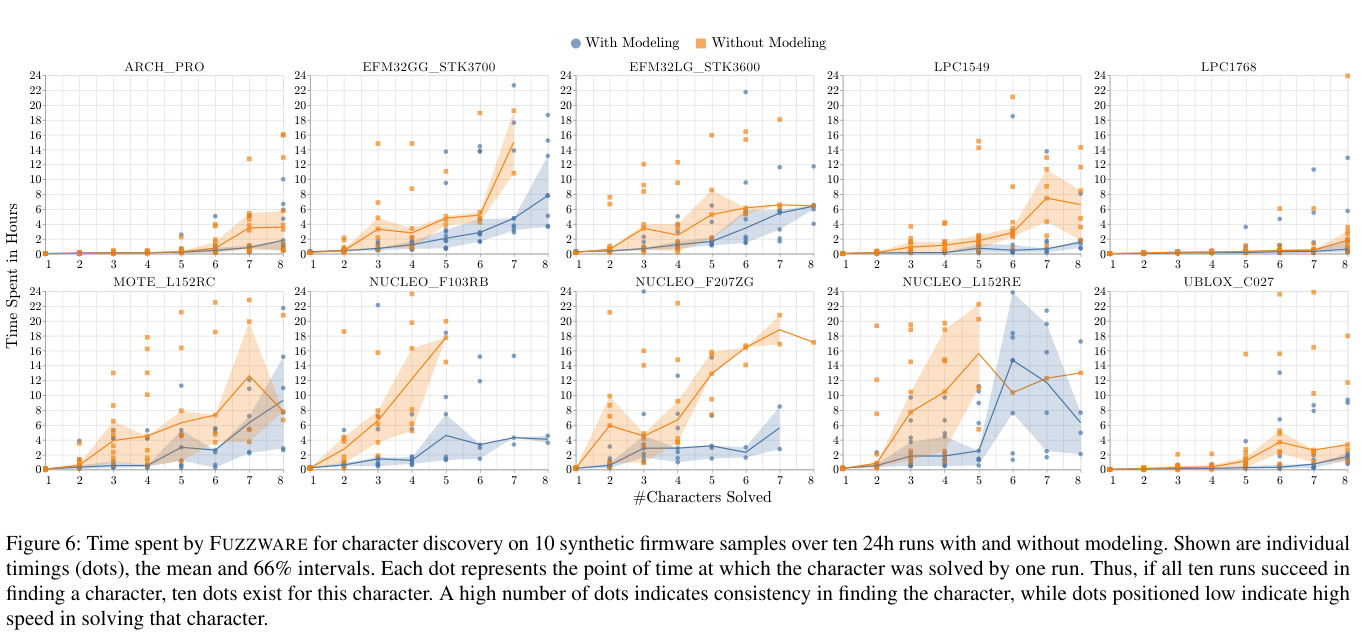
- 一组实验定义为:分别在使用MMIO建模和不启用建模的情况下,在10个Mbed OS支持的硬件平台上对测试程序进行24小时的fuzz。这样的实验一共进行了10组,Figure 6中可视化了各个字符所花费的时间。
-
实验得到的一些额外指标
-
模型生成损失:为了更好的回答RQ1,评估一次建模产生的计算成本,实验统计了所有模型生成过程需要的时间。在24小时的实验过程中,针对单个固件映像平均生成了62个模型,平均计算时间为6.34分钟(每个模型6秒)
-
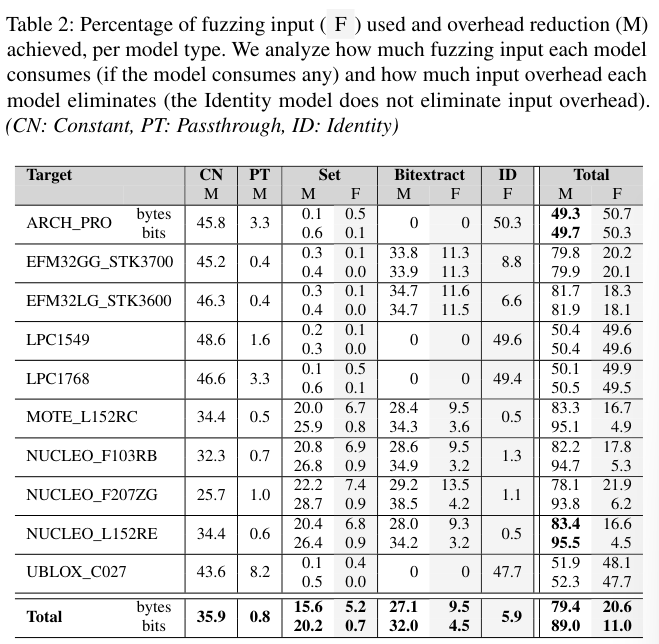
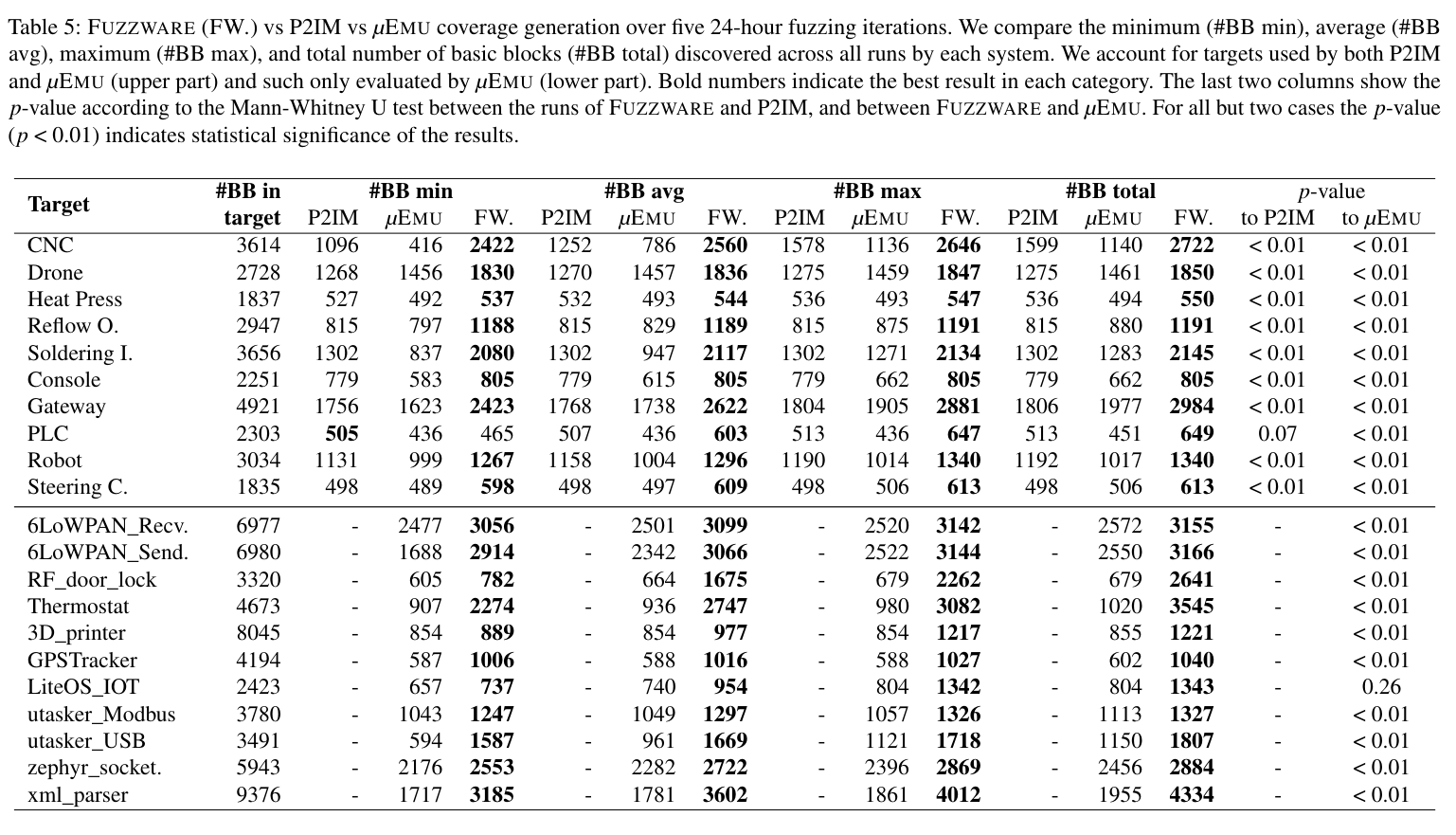
输入开销消除:量化了MMIO建模对于输入开销的消除效果。table 2展示了不同模型消除了多少输入开销(M)以及它们消耗了多少模糊输入(F),表中每格多出来的一行用来显示在假想的位粒度模型下,实现的输入开销消除的比率。
可以看到(total一行中),平均情况下,输入开销的消除比率到达了80%,使用位粒度这种消除比例将达到90%。
另外对于不同的硬件平台,输入开销也有很大的差别。对于具体的固件样本来说,一些MMIO建模类型也可能完全不适用,例如如果MMIO访问的位宽与固件代码中实际使用的数据位完全一致时,Bitextract模型将不起作用(不需要使用掩码)。
-
没有被消除的输入开销:需要统计和分析ID模型(没有消除任何输入开销)。实验过程中总共产生了623个模型,其中有34个是ID模型,作者手动验证了这些模型。其中有19模型实例需要使用完整的输入值,无法进行输入开销的消除;另外15个实例由于达到了DSE设置的资源限制条件,因此被保守的分配了一个ID模型并回退到允许模糊器尝试所有值。
文章认为这种回退情况将很少发生,因为固件通常在读取硬件生成的值后立即处理它,因为 MMIO 寄存器的状态是短暂的,并且可能会在很短的时间内发生值的改变。
-
MMIO访问模型的通用性:P2IM的作者发布了一组46个固件映像,包括66个单元测试用例,用来测试一个仿真系统在不同固件和硬件平台组合时,处理各种类型的常见外设,以及处理基于中断和同步的消息传递机制的能力。之前工作的通过率是83%(P2IM)和95%(µEMU ),而fuzzware则是第一个100%通过了所有66个测试用例的自动化通用仿真系统。——稳健性、普适性以及不依赖路径消除方法的优势
-
-
-
与现有技术的对比——与 µEMU 和P2IM进行了比较(两种最先进的无硬件re-hosting工具)
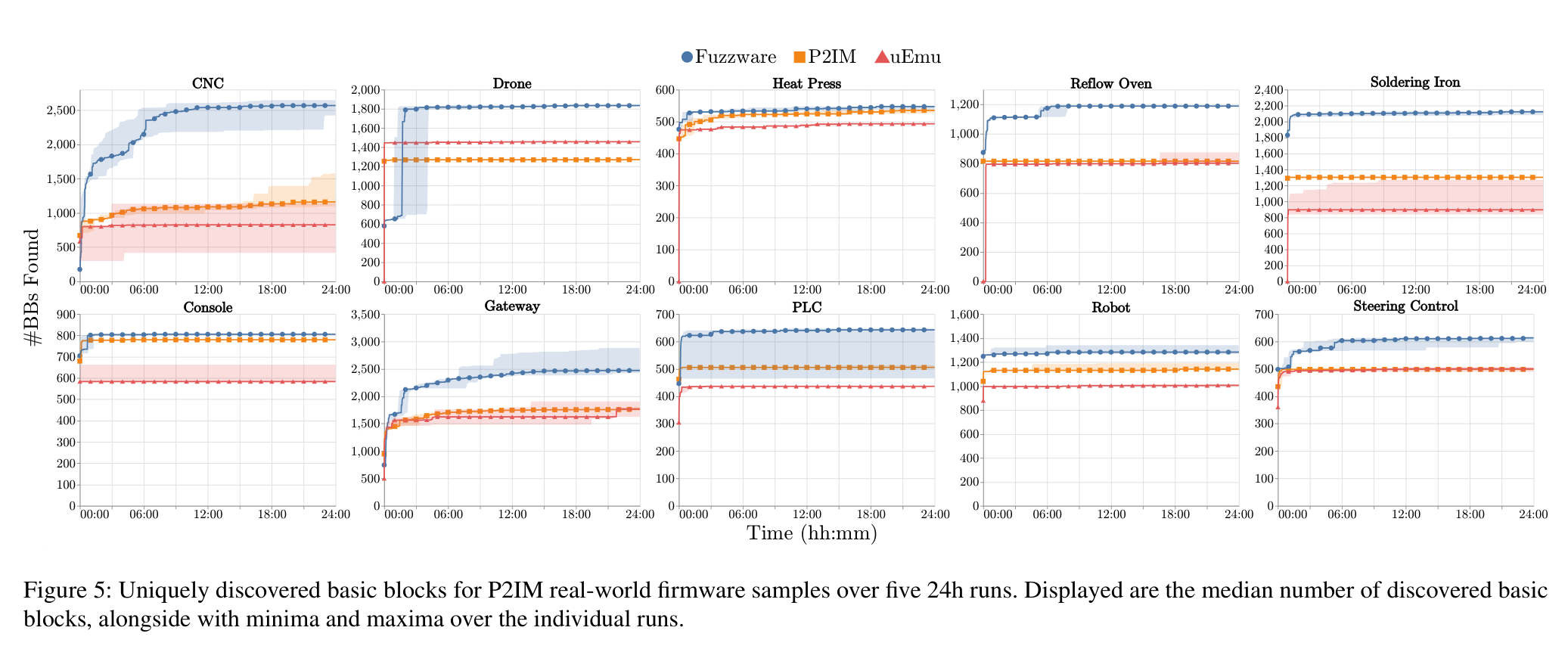
-
测试样例:µEMU 提供的21个真实固件样本(其中包含了P2IM先前测试的10个样本)
与fuzzware的配置相比,µEMU需要设计输入外设的定义,需要自定义配置来调整目标的探索参数,还需要自定义路径有效性相关的信息,这些配置都需要有十分专业的研究者来进行指导,在没有这种人工协助的情况下P2IM将无法分析µEMU新加入的11个样本。因此在Figure 5中实际上只展示了P2IM能够测试的10个样本的运行结果。
-
测试过程:每个样本都在Ubuntu18.04LTS(CPU:Intel Xeon Silver 4114,主频:2.20GHz)环境下执行了5×24小时的模糊测试迭代。对于所有实验,都尽可能使用原来的配置。除了5个样本使用了µEMU 的部分配置之外,fuzzware总是使用默认配置。在其中四个样例中,实验禁用了中断(3D_printer、RF_door_lock、Thermostat、xml_parser),第五种情况中,文章手动为两个DMA缓冲区地址MMIO寄存器(utasker_Modbus)定义了直通模型来提供对DMA的支持。
-
测试结果:与现有技术相比,fuzzware能够十分显著的提高代码覆盖率。 在10个样本的测试中,fuzzware的代码覆盖率平均比P2IM高约44%,相比µEMU提高约61%(与µEMU在全部21个样本上平均高约57%)。
可以看到P2IM的运行效果往往比µEMU要好,文章认为这是由于µEMU过于积极的路径消除导致的:µEMU框架通过启发式方法来决定可行的执行路径并提供硬件值,当无法做出明确的区分时,µEMU将会随机决定执行路径,这种方式可能导致要么大部分的固件逻辑可以被分析到,要么它们将完全从当前运行过程中被删除。作者认为这两种框架的路径消除方法都会导致基本块发现过程提前结束(从图上可以看到,两条曲线很早的就趋于水平不再变化了),最终在代码覆盖率上不如fuzzware。(回答了RQ4)
除了代码覆盖率和自动化程度的显著提高之外,fuzzware还从三个实例中挖掘到了之前没有被发现的bug,手动分析表明,fuzzware发现了一个并发问题(Soldering Iron),一个未经检查的指针(CNC),以及一个AT指令解析崩溃的问题(GPSTracker)(回答了RQ5)
-
-
尝试新的fuzz对象(拓展RQ3和RQ5)
-
新对象:两个使用广泛的嵌入式固件框架Zephyr 和 Contiki-NG,测试他们的核心网络协议栈的不同功能。主要选择了两个系统的无线电层作为模糊测试的目标,因为相连的设备将会十分依赖于协议栈,对应的低级解析代码暴露了一个通用的攻击面。
如果能够成功的实现攻击,产生的影响可能从一台设备传播到另外一台设备,因此这类接口中的缺陷将会使整个设备群面临风险。
-
结果:fuzzware总共在这些目标中发现了12个不同的漏洞,在经过协商漏洞披露之后为此分配了12个CVE,对其中的一些漏洞进行案例研究。
-
CVE-2020-12141(缓冲区溢出):在 Contiki-NG 的测试版本中,简单网络管理协议(SNMP,Simple Network Management Protocol )在处理接收到的SNMP报文段时没有验证用户提供的可变字段community的大小,这可能会产生缓冲区溢出,并且导致固件崩溃(Dos)
-
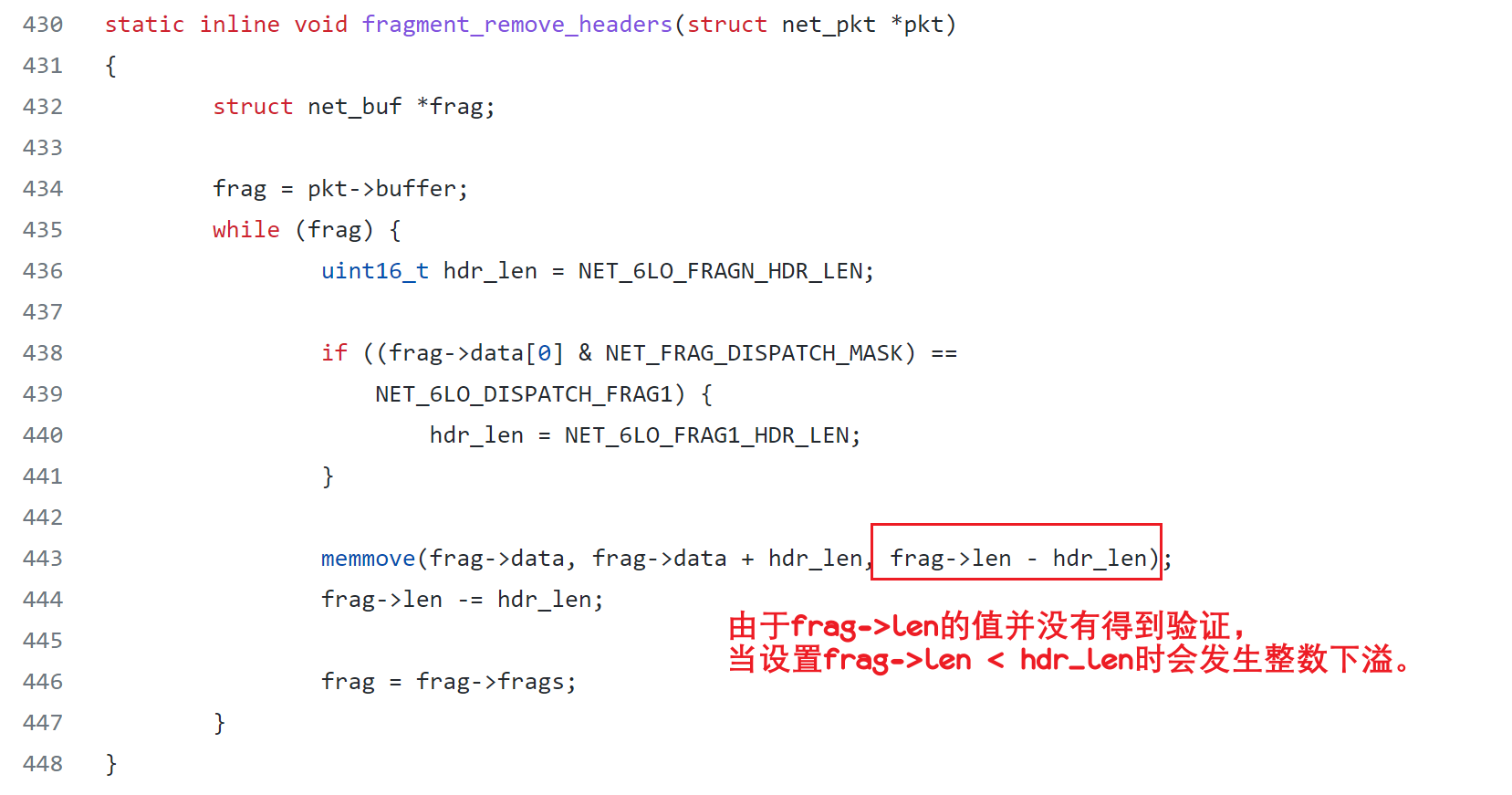
CVE-2021-3321(整数溢出):作为从无线电帧到 IPv6 数据包的转换层,IPv6 over Low-Power Wireless Personal Area Networks (6LoWPAN) 标准定义了一种报头压缩机制。在解压之前,Zephyr 检查了解压后的头部负载所需的大小,并会分配一个适当大小的目标缓冲区来保存解压后的内容。然而,该逻辑并未检查源帧是否实际上大到足以容纳压缩的报头有效载荷。 结果,它从帧保存缓冲区中消耗了比可用字节更多的字节,导致大小字段整数下溢,随后内存损坏。

-
CVE-2021-3330(片段重建排序算法漏洞):为了从小型无线电帧传输 IPv6 数据包,6LoWPAN 定义了一个分段层。为了区分片段列表的开始条目和后续条目,帧被分别分配了片段类型 FRAG1 和 FRAGN。当遇到 FRAGN 片段时,重组逻辑会将片段插入到片段列表的开头,并正确检查其内容是否标记为在重组缓冲区的开头插入。然而,在重新组装之前,逻辑并未检查是否存在 FRAG1 片段。假设存在 FRAG1 片段,片段排序逻辑将在预排序的第一个元素上预测其算法。使用一组精心设计的输入片段,它们与所需的整体大小完全匹配,但不包含 FRAG1 片段,排序逻辑可以被欺骗在列表中创建一个意外的循环引用,这会转化为最终的整数下溢,然后是缓冲区溢出。
-
-
崩溃分析

-
简要数据:实验过程中总共产生了61次崩溃,其中有42次是因为固件漏洞引起的,16次是因为固件逻辑没有严谨的处理初始化过程(例如没有检查初始化API的返回值),剩下的三个崩溃案例与固件逻辑上的漏检有关。
Table 3中的统计结果已经对重复的崩溃样例进行了删除。之所以将剩下三种崩溃情况定义为误报的情况,是因为在这三种情况中,尽管固件逻辑上存在导致崩溃的隐患,但是由于外设的具体设计,导致实际在硬件上运行时这种崩溃可能永远不会发生
-
Zephyr 中发生了两次这样的崩溃:在第一个案例中,无线电数据包的长度被隐式假设为最大值 127,而硬件生成的 MMIO 值的完整字节被使用而没有检查size变量(最大值值:255),这会导致size值大于 127 的缓冲区溢出。在第二个案例中,中断处理程序使用了没有进行初始化检查的指针变量。它假定在引发中断时初始化变量。如果在执行此初始化之前由模糊器引发中断,则中断处理将导致空指针解引用(使用空指针崩溃)。
-
第三次误报崩溃是在 µEMU utasker_USB 样本中产生的:其中 USB 接收通道号寄存器字段 CHNUM 的最大值可能为 15,但实际上在使用的USB通道并没有这么多,这可能导致越界访问和崩溃。
-
小结:Fuzzware的仿真和模糊测试的过程是不依赖于硬件实现的,fuzzware不关注硬件环境如何,只是尝试去发现固件中可能存在的漏洞和错误,有些错误在实际硬件平台上可能永远不会发生,从这种角度来说,这类固件代码只是表明开发人员信任对应的硬件环境。以上三个崩溃样例说明即使是对于同一份固件代码,在不同的硬件环境中执行时也可能存在不同的安全风险,通过这种方式,fuzzware甚至可以在固件代码部署到不同硬件环境之前发现可能的安全问题。
在第一个案例中,如果硬件在设计过程中可能不会产生MMIO大于127的输入,这种崩溃就不会发生;
在第二个案例中,硬件设备不会以这种时序来触发中断时,这种崩溃现象就永远不会发生;
在第三个案例中,只要保证硬件设计不会产生非法的USB通道值MMIO输入,这种崩溃就不会发生。
-
讨论和展望
- 有关DMA建模:fuzzware并没有实现自动化DMA建模,只允许通过附加配置来处理DMA,因为自动化DMA建模不是本项工作的重点。但是fuzzware依然为自动化DMA处理做出了很大的贡献:由于DMA处理的固件代码通常是更加复杂代码的一部分,实现更大范围的代码覆盖将成为触发那些深藏在复杂逻辑中的DMA处理的先决条件。论文DICE(一篇21年的通用DMA处理方法的论文)的评估表明以前的固件模糊测试系统由于代码覆盖率的原因无法到达DMA逻辑。
- 在fuzzware之外的地方使用MMIO访问模型:意在回答fuzzware中设计的MMIO访问模型是否能够在除了fuzzware以外的其他地方独立使用的问题。由于在生成了访问模型之后,服务需要提供的信息就只有访问规模、位置信息和程序计数器的值,这些信息在其他的分析框架中也很容易获得。为了证明访问模型的可移植性,文章将访问模型集成到了avatar2中,这使得动态分析功能不只局限于模糊测试,也能够使用PANDA框架进行污点分析。
- 路径消除的优点:之前的很多研究通过消除代码路径的方式来引导固件执行,但是消除路径就要承担将相关逻辑排除在分析之外的风险。启发式的代码路径分类很容易出错,并且错误分类需要人工干预才能够修复。为了促进自动化,fuzzware允许碰到卡住的情况(无限错误循环),并且依靠模糊引擎通过超时和覆盖率反馈来避免这种情况。未来的工作可以通过识别和消除可以安全移除而不减少可访问固件逻辑数量的卡壳情况来对系统进行优化。
- 隐含的外设工作语义:实验发现固件逻辑对于外设的硬件行为会做出一些隐含的假设,例如一些隐含的大小限制,假定一些事件发生的先后顺序等。固件代码的这种构建和操作方式方面的特征所隐含的信息对于推导出更加复杂的外设行为模型可能具有重要的意义。