CHUNKED-CACHE: On-Demand and Scalable Cache Isolation for Security Architectures
针对Cache的侧信道攻击
- 基于访问的攻击
- 向缓存中填充随机数据
- 触发加密行为
- 访问之前填充的数据并计时
- 基于驱逐的攻击
- 触发加密行为
- 驱逐一部分缓存行
- 再次触发加密行为并计时
- 基于占用的方法
- 观察自己的缓存行被逐出,并使用此信息推断受害者工作集的大小
常见防御方法及其缺点
- 观察自己的缓存行被逐出,并使用此信息推断受害者工作集的大小
-
具有侧信道抗性的方法
如使用常数时间的密码算法。因硬件平台而异,且不可推广和扩展到其他软件,开发难度大
-
检测攻击
通过观察硬件性能计数器(例如,缓存未命中率)并杀死可疑进程。只能以一定概率发现攻击,且有些攻击方法已被证明不会引起缓存行为异常。
-
注入系统噪声
阻止攻击者执行精确的时间测量。例如限制对计时器的访问,通过向系统注入噪声或故意减慢系统时钟。然而有些变通方式可以在不访问计时器的情况下进行。并且无法保护 TEE 架构。
- 缓存级防御
-
随机缓存行映射
不能提供面向未来的安全保证。例如攻击策略和最小驱逐集构造技术的进步,此外,替代攻击技术已被证明会破坏这种防御。
依赖于密码学方法,可能被密码分析破解。部署更安全的方法会进一步降低性能
-
缓存分区以提供严格的缓存隔离
现有的分区防御性能开销较大、限制多,缓存利用率低、无法支持大数量的保护域。
有些方法不支持共享库的使用;或特定于某些架构;或无法防御基于占用的攻击。
内存页面着色方法需要对软件的内存管理进行修改,并且不能充分支持DMA(Direct Memory Access)。
现有的分区防御将其侧信道缓存保护应用于整个工作负载,从而影响系统整体性能,而这在大多数情况下是不需要的。
CHUNKED-CACHE采用的缓存隔离
- 为相互不信任的执行域提供严格但可配置的缓存分区。
- 对于每个域,仅在域需要时划分并隔离一个独占的缓存。
- 能有效地减轻来自跨域的干扰和攻击,甚至可以防御隐蔽的缓存占用攻击。
- 所有其他执行域可以共享使用非独占的缓存。性能与传统的非安全缓存相同甚至更高。
摘要
多核处理器中的共享缓存资源容易受到缓存侧信道攻击。最近提出的防御措施,如将地址随机映射到缓存行或众所周知的缓存分区,都有自己的缺点:基于随机化的防御措施依赖弱加密原语,并且容易受到新的攻击算法的攻击。它们不能从根本上解决缓存侧信道攻击的根本原因,即共享缓存资源的代码之间相互不信任。缓存分区防御提供了有效阻止所有侧信道威胁所需的严格资源分区。然而,它们通常依赖于way-based的分区,这种方式无法实现细粒度的分区,并且不能扩展以支持更多的保护域,例如在可信执行环境(TEE)安全体系结构中,并且还往往导致性能降低和缓存利用不足。 为了克服这两种方法的缺点,我们在TEE(可信执行环境)上提出了一种新颖灵活的组相连缓存分区设计,称为CHUCKED-CACHE。CHUNKED-CACHE的核心思想是,如果执行域需要侧信道抗性,则允许执行上下文“切割”出一个独占的可配置的缓存块。如果不需要侧信道抗性,则可以自由利用共享的缓存资源。我们的解决方案CHUNKED-CACHE通过提供高效的可选择性和按需使用的具有侧信道抗性的缓存,从实际上解决了安全与性能的折衷问题,同时提供了可靠的未来安全保障。我们发现,CHUNKED-CACHE为敏感代码执行提供了侧信道弹性缓存利用率,硬件开销较小,同时在操作系统上不会产生性能开销。我们还表明,它的性能比传统的way-based缓存分区方案高出43%,同时可以更好地扩展以支持更多数量的保护域。
贡献
- 我们提出了CHUNKED-CACHE,这是一种用于TEE安全体系结构的新型缓存体系结构,它能够在不降低操作系统性能的情况下,为执行域提供选择性、灵活和可扩展的侧信道抗性缓存配置。
- 我们通过强制执行干净的缓存分区,通过为不同的域分配专用缓存块来阻止所有缓存端通道,从而解决性能-安全权衡问题。在这样做的过程中,可以提供对未来的可靠的安全保证,同时仍然保持性能、功能和兼容性要求
- 对于计算密集型SPEC CPU2017工作负载和I/O密集型实际应用程序,我们广泛评估了分块缓存的周期精确性能开销。我们发现,在某些情况下,CHUNKED-cache的性能甚至优于共享缓存利用率,CHUNKED-cache灵活的缓存利用率甚至提高了操作系统的性能,CHUNKED-cache的性能比基于分区的方法高43%,同时还可以更好地扩展以支持更多的保护域。
- 我们实现并评估了CHUNKED-CACHE的硬件原型。我们表明,相对于16MB LLC,它产生的内存开销最小为2.3%,相对于单核RISC-V处理器,产生的逻辑开销最小为1.6%,LLC功耗开销最小为12.3%。
威胁模型
- 攻击环境
- 部署于TEE架构上的Chunked-Cache
- 操作系统内核与hypervisor不受信任
- 攻击目标
- 泄漏I-Domain的敏感信息
- 攻击者的能力
- 进行基于访问、基于冲突、基于占用侧信道攻击
- 了解Chunked-Cache的设计与实现
- 知道受害者域从虚拟地址到物理地址的映射
- 可以从高特权级发起攻击
- 能够精确的测量时间并能使用驱逐缓存行指令(clflush)
- 从受害者相同或不同的CPU内核发起攻击
- 能自由打断受害者执行,能尽可能减小来自系统的噪声
Chunked-Cache设计
总体设计
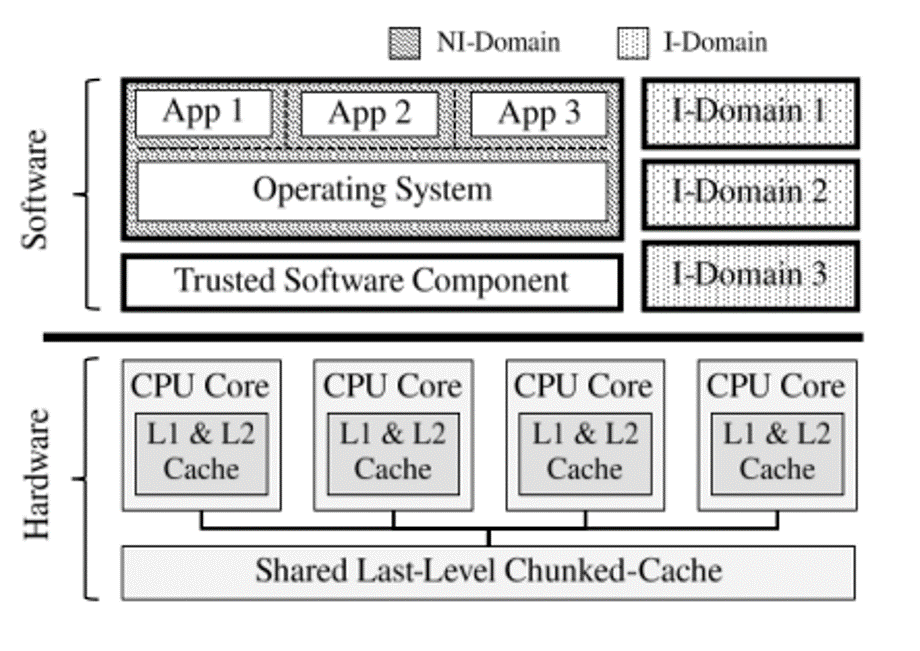 将不同软件划分为I-Domain与NI-Domain。
将不同软件划分为I-Domain与NI-Domain。
I-Domain拥有自己独占的缓存资源,所有NI-Domain与操作系统共享剩余的缓存资源。
使用Trust Software Component保护Chunked-Cache元数据。
硬件上,所有CPU内核共享最后一级缓存,Chunked-Cache被集成在最后一级缓存中。
域划分设计
 每个活动域(NI-Domain 和 I-Domain)都由一个 ID 唯一标识:DID。
每个活动域(NI-Domain 和 I-Domain)都由一个 ID 唯一标识:DID。
操作系统 (OS) 和所有不需要保护的工作负载(并在 NI 域中组合)被分配 DID 0。
每个 I-Domain 都可以请求所需容量的独占缓存资源,形成域的独占缓存块,仅由所有者域使用。
NI-Domain 使用了未被专门分配给 I-Domain 的缓存集,称做Mainstream Cache Set。
该种设计具有如下优势:
- 性能上:不会与其他工作负载竞争;按需分配,最大化缓存利用率。
- 与固定分配相比,CHUNKED-CACHE 在缓存微架构中提供了自适应的安全性。 一方面,可以允许非敏感工作负载自由使用共享的主流缓存资源。
- 如果需要考虑侧信道弹性,则可以将具有默认容量的缓存块分配给每个 I-Domain,而无需开发人员的任何进一步干预。 只有当开发人员需要进一步优化特定 I-Domain 中的工作负载性能时,如果负担得起/可用,则可为 I-Domain 分配更多缓存资源。
流程设计
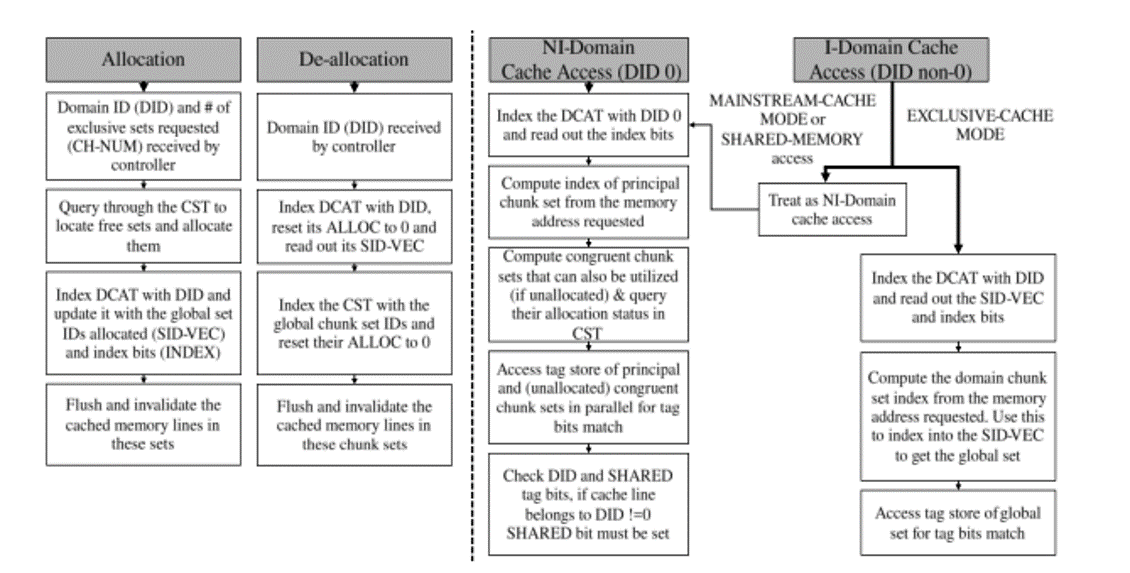 包含4种基本流程:
包含4种基本流程:
- 独占缓存的分配
- 独占缓存的释放
- NI-Domain对缓存的访问
- I-Domain对缓存的访问
域隔离模式配置设计
根据 TEE 的设计范式,假设所有工作负载都需要缓存隔离和侧信道抗性是不合理的。
每个 I-Domain 可以针对其保护的工作负载进行选择性配置:
- MAINSTREAM-CACHE 模式:不需要缓存隔离和侧信道抗性时,I-Domain 可以使用Mainstream缓存。但此时,缓存的 I-Domain 数据仍必须受到保护,以防止恶意操作系统访问。
- 独占缓存模式:需要缓存隔离以获得侧信道抗性时,会被分配由该域独占的缓存。
-
I-Domain 还可以配置其共享内存设置。
当使用操作系统服务时,需要与操作系统共享内存区域(和缓存行),否则会产生较大的性能开销。为了缓存共享内存,需要使用操作系统使用的Mainstrean缓存。
开发者需要对I-Domain 进行配置:
- 其缓存所需的隔离模式
- 需要共享的内存区域
Chunked-Cache元数据由可信组件安全地自动配置
工作负载的开发人员决定 I-Domain 使用哪种隔离模式并确定需要共享哪些内存区域,这与 TEE 架构中的要求相一致,开发人员必须识别整个工作负载的安全敏感部分。如果开发人员不确定缓存侧信道攻击是否构成威胁,则应谨慎选择独占模式
Mainstream Cache与共享内存设计
- Mainstream Cache
- 当 I-Domain 处于 MAINSTREAM-CACHE MODE 时,它使用 OS 也使用的Mainstream Cache(DID 0)。
- 为了防止恶意操作系统将 I-Domain 的内存映射到自己的内存空间并直接在缓存中访问,CHUNKED-CACHE 要求缓存行带有域 ID DID 标记。
- 作为硬件实现,操作系统无法修改存储在缓存行中的 DID。
- 共享内存
- 当 I-Domain 也与 OS 共享内存时,已定义的 SHARED MEMORY 区域对应的缓存行缓存在主流缓存集中,并由所有者域和 OS 访问。
- 缓存行需要用一个额外的 SHARED 标志来标记,该标志指示缓存行是否与操作系统共享。
存储Cache Tag和Cache Controller
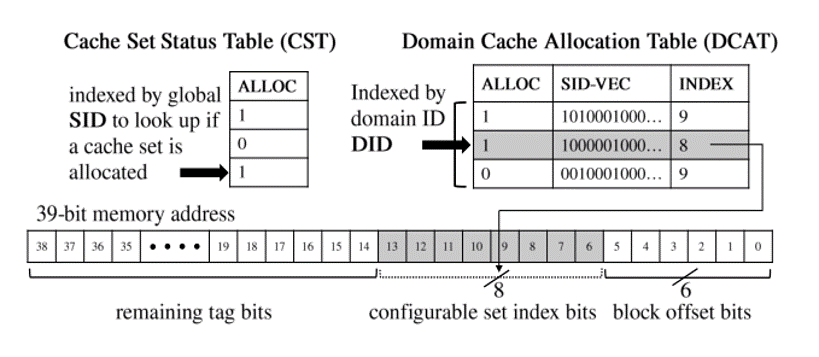 缓存行需要额外标记域 ID (DID) 位以及 1 位 SHARED 标志位,以实施访问控制和与 NI 域的适度共享。
CHUNKED-CACHE 控制器需要 2 个表结构
缓存集状态表 (CST) 由SID索引,表示每个缓存集的分配状态
域缓存分配表(DCAT)由DID索引。表示此域是否被分配哪些缓存集合
缓存行需要额外标记域 ID (DID) 位以及 1 位 SHARED 标志位,以实施访问控制和与 NI 域的适度共享。
CHUNKED-CACHE 控制器需要 2 个表结构
缓存集状态表 (CST) 由SID索引,表示每个缓存集的分配状态
域缓存分配表(DCAT)由DID索引。表示此域是否被分配哪些缓存集合
独占缓存模式下的缓存集索引
为了使 CHUNKED-CACHE 支持不同域的不同大小的缓存块,需要可配置的集合索引。 在配置时,根据保护域请求的缓存集数量,计算索引的位数,存储在元数据中;当域发出内存访问时,查找此元数据。 当 I-Domain 被释放时,除了刷新和使缓存行无效之外,还需要相应地更新相关元数据。 支持在运行时为 I-Domain 的缓存块分配额外的缓存集,并相应地重新配置索引位
缓存集的分配和释放
分配 使用受信任的安全组件将请求写入缓存控制器的配置寄存器 请求包括DID、请求的集数 (CH-NUM) 以及相应的 INDEX 位数 (log2 CH-NUM) 在DCAT中检查该域已分配的缓存集数量是否超过最大值 查询CST以定位空闲的缓存集,并翻转ALLOC位 如果CST中空闲集数量不足,告知安全组件以修改请求 更新DCAT中的SID-VEC以及INDEX位 释放 通过DID读取DCAT,重置ALLOC ,读取 SID-VEC 。 使用 SID-VEC 中的每个集合 ID 对 CST 进行索引并取消分配 无效相关缓存行,如果脏则需要刷新
NI-Domain的缓存集索引
系统刚启动时,除操作系统外没有其他域,默认情况下所有缓存集都分配给操作系统。 这些缓存集被称为mainstream缓存集。 一旦其他域请求独占缓存集,一部分缓存被分配给保护域独占。 这导致mainstream cache的容量改变,同时索引也会改变。 这会使 OS 已经缓存的所有内存行全部失效。 解决方法:将足够大数量的缓存集固定的分配给操作系统。
解决方法:将足够大数量的缓存集固定的分配给操作系统。

Cache的访问策略
NI-Domain OS被分配了固定的缓存集,因此索引位固定,无需查找DCAT 同时也可以使用未被分配的缓存集,与上一步并行计算,没有额外的延迟 同时并行检查DID 和 SHARED 标签位 I-Domain 如果是mainstream模式或者共享内存模式,则与NI-Domain的访问一样 如果是独占缓存模式,根据DID索引DCAT中的表项,读取INDEX的位数,计算索引值 通过索引值和SID-VEC得到缓存集的全局ID 比较标记位
缓存替换策略
CHUNKED-CACHE 的设计与缓存替换策略独立 按照I-Domain和NI-Domain的缓存访问策略选择缓存集,替换其中的缓存行
安全性
保护能力依赖于对缓存资源的严格分区 受信任的软件组件将分配给I-Domain的缓存集数量传递给缓存控制器 缓存控制器配置DCAT,验证每个缓存集只被分配给一个I-Domain 攻击者无法访问或驱逐I-Domain独占的缓存集 防御基于访问的、基于驱逐的、基于占用的侧信道攻击 在修改I-Domain的缓存块容量时,所有分配给该域的缓存集都将失效 防止了缓存集被分配给其他域时造成的信息泄露 也防止了其他域可能留下的有害数据 防御来自NI-Domain的攻击 特权级操作系统可能尝试将受害者的物理内存映射到自己的内存空间,并从缓存中访问 每次访问mainstream缓存时,检查DID是否匹配
由于DID的分配与DCAT的配置只有受信任的软件组件执行,缓存控制器永远不会返回不属于内存所有者的缓存集
CHUNKEDCACHE 严格的缓存资源分离可以防止攻击者观察到由受害者引起的对自己集合的驱逐,从而防止基于占用的攻击
硬件实现
- 缓存标记位
- 4位DID,标记缓存行的所有者
- 1位SHARED位,标记是否共享
- 16路16MB LLC
- CST
- 16384位寄存器,表示16384个缓存集的分配状态
- DCAT
- 16行,以支持16个域同时运行
- ALLOC标志,1位
- SID-VEC,最多支持8196个缓存集,每个缓存集需要14位,共114688位
- INDEX,表示缓存索引的长度,最大为log2(8196)=14,4位
- CST
- 使用有限状态机管理缓存的分配、释放与访问
性能评估
测试环境
- 测试环境
- Intel Xeon Silver 4215 CPU (2.50 GHz)
- 16 GB RAM
- 测试工具
- 标准SPEC CPU2017基准测试
- SPECspeed 2017 Integer
- SPECspeed 2017浮点套件
- 测试目的
- 衡量CHUNKED-CACHE对现实世界工作负载的性能影响
- 比较对象
- 未修改L3的不安全缓存
- 基于缓存路分区的L3缓存
- 将缓存路独占分配给I-Domain
- 测试细节
- 在周期精确的gem5模拟器上实现了CHUNKED-CACHE,并构建了一个多核系统
- 该系统类似于一个包含三级缓存层次的现代计算系统。每个核心都可以访问核心专用的一级和二级缓存,以及所有核心共享的三级LLC。对于L1和L2,我们使用gem5提供的未修改缓存实现,而对于L3缓存,我们使用分块缓存实现。
I-Domain性能影响
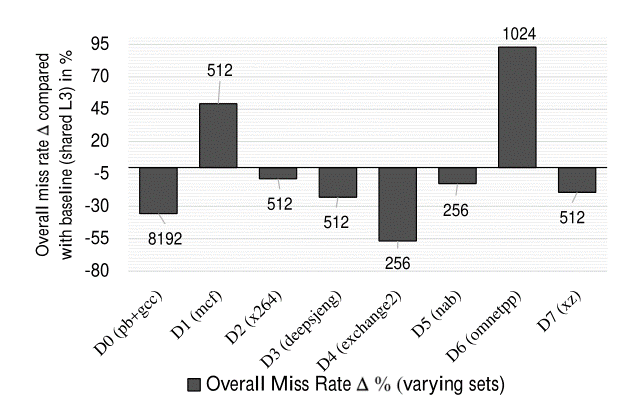
- 域的分配
- I-Domains : 7 个随机选择的SPEC benchmarks
- 按需分配了不同的set数量
- NI-Domain (D0) :Linux (kernel version 4.19.83) 和2 个具有较大工作集的benchmarks (600.perlbench_s and 602.gcc_s)
- I-Domains : 7 个随机选择的SPEC benchmarks
- 分析
- 大多数负载的未命中率显著降低。对于缓存未命中率上升的负载,表明该负载需要更多的缓存行
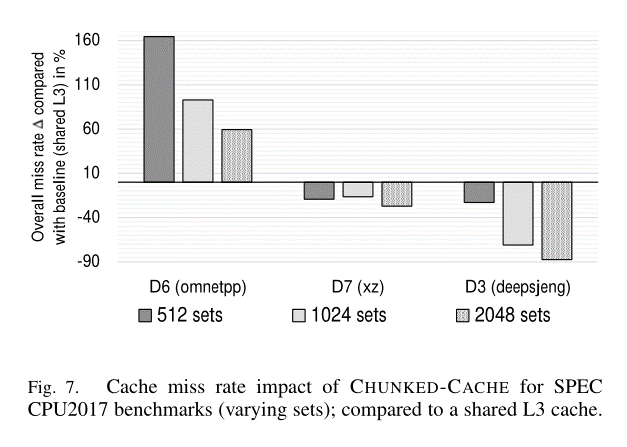
- 分析
- 随着被分配的chunk size增加,性能显著提升

IO敏感负载 Nginx服务器 Wrk使用12线程创建400个连接 防止了Nginx和Wrk内存相互逐出
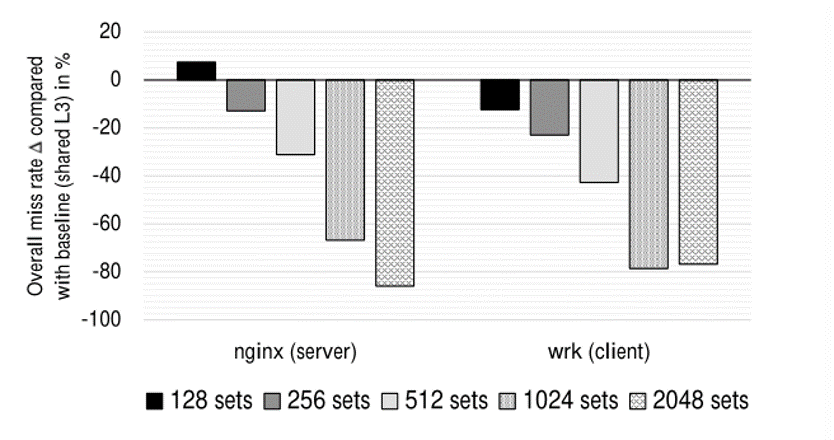
NI-Domain性能影响
- 测试环境
- IDomains
- 运行 SPEC 基准测试中的混合工作负载
- NI-Domain
- Linux 和 2 个内存密集型基准测试 600.perlbench_s 和 602.gcc_s
- 分配给 NI 域的集合数量从 2,084 变为 8,192
- IDomains
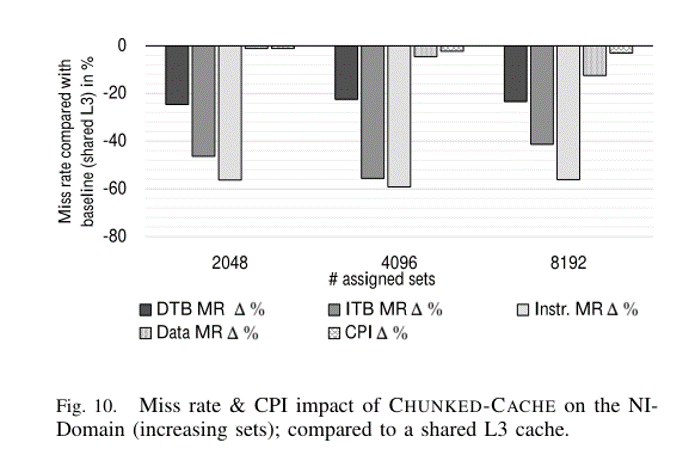
- 指标
- 页表遍历器的数据和指令未命中率
- CPU核心的数据和指令未命中率
- CPI
- 性能
- 未命中率和CPI随着块大小从2048增加到8192略微下降
- 分析
- 即使仅给NI域分配少量的缓存,但NI域仍可利用未被分配的缓存
- NI-Domain 的性能不会受到显着影响,并且保留了可用资源的最大利用率,这是 CHUNKED-CACHE 的设计目标之一。
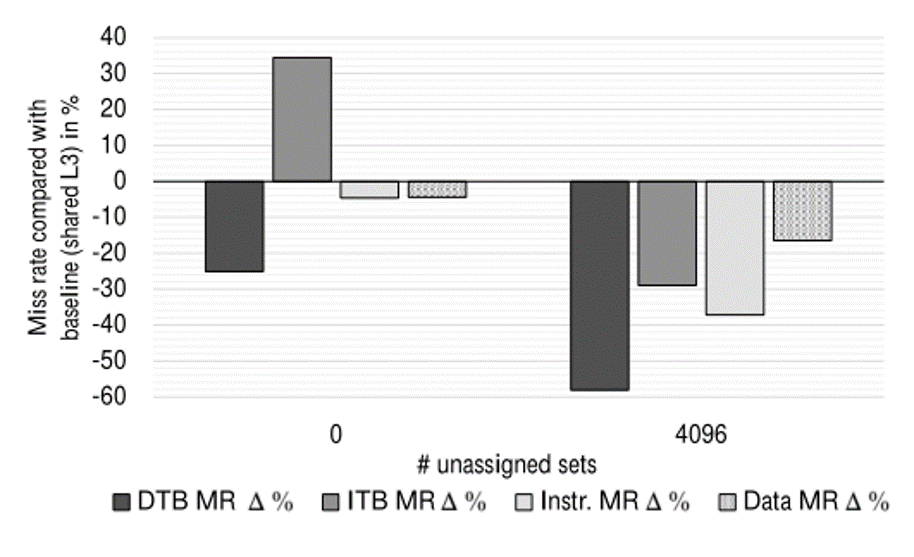
- 将 1,024 个集合分配给 NI 域并改变未分配集合的数量。
- 所有缓存都被分配与4096个缓存集未被分配
- 4096个缓存集未被分配时,缓存未命中率显着降低
- 分析
- 这展示了 CHUNKEDCACHE 如何使 NI-Domain 能够利用未使用的缓存集。
与基于分区的方法的比较
- Way-based缓存分区
- 5个域
- 同一个域设置相同的容量
- 1024个set相当于1个way
- 缓存未命中率
- 1MB缓存容量(1024个set)下,平均降低43%
- 2MB缓存容量(2048个set)下,平均降低39%
- 对于某些基准测试,例如 625.x264_s 和 644.nab_s
- 分配 1,024 个集合甚至在路分区缓存上优于 2 路(缓存容量翻倍)
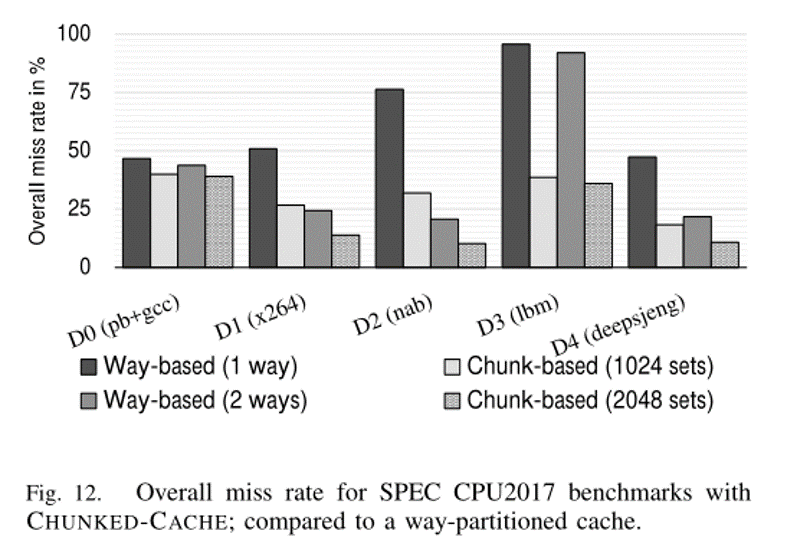
- 分配 1,024 个集合甚至在路分区缓存上优于 2 路(缓存容量翻倍)
性能开销
存储/内存开销
- 所需的额外存储空间
- DCAT ≈ 224 KB,额外的标签需要 160 KB, 总计 386 KB
- 与 16 MB LLC 相比
- 存储开销2.3%
- 额外制造面积大约 2.7%
- 影响开销的因素
- 支持的域的数量:线性增加
- 例如,为了支持 32 个域,相对于上述 16 个域所产生的开销
- 多一个标记存储位,这额外花费了 0.25KB
- CST 容量不受影响
- DCAT 容量翻倍至 448KB
- 功耗将按比例增加
- 总L3缓存容量
- 域最大缓存集数量
- 支持的域的数量:线性增加
逻辑开销
- CHUNKED-CACHE 需要额外的 FSM 硬件逻辑来处理缓存解除/分配,并在缓存访问之前查找表。
- 使用 Xilinx Vivado 面向 ZedBoard Zynq-7000 FPGA 板进行评估
- 相对于该单核 RISC-V 处理器,约 1.6% 的逻辑开销。
- 逻辑开销不会随着 CHUNKED-CACHE 支持的域数量的增加而增加
功耗开销
- 额外硬件包括CST与DCAT表
- 测试环境
- CACTI-6.0 工具
- 22nm制程下
- 16路总大小16MB的LLC,缓存行大小64B的Chunked-Cache
- 测试结果
- 总泄漏功率从 5056.57 mW(基线)增加到 5313.83 mW
- CST 和 DCAT 产生额外的 365 mW,LLC 功耗总共增加了 12.3%
- 影响开销的因素
- 随着操作系统并行查找缓存块的数量的增加而增加
- 默认2个缓存块并行(操作系统被分配8192个缓存集)
- 4个缓存块并行:额外5.5%
- 8个缓存块并行:额外27.1%
- 随着操作系统并行查找缓存块的数量的增加而增加
- 测试结论
- 现代多核处理器功耗为90-150W,Chunked-Cache产生的功耗开销与之相比非常小
相关工作
与基于分区的微架构的比较
- 将缓存资源(cache lines或ways)专门分配给受保护的域。
- 基于TEE体系结构的Keystone和CURE实现了基于way的分区,将cache way独占的分配给Enclave。
- SecDCP为有类似安全需求的应用构造安全类,并为它们分配不同的cache way。
- DAWG针对预测执行攻击的情况,提供了基于way的缓存分区
- 基于way的分区的缺点:
- 无法并行支持大量保护域。即使是大型LLC也只包含少量缓存way(最多16个)
- 缓存利用率不足。系统上所有其他域未使用的缓存行都会被阻塞
- 应用无法均匀利用缓存行时,缓存利用率低
- 基于缓存行的分区
- Plcache
- 将缓存行独占的分配给允许对缓存资源进行严格的细粒度分区的进程
- 不允许进程间共享缓存数据,影响整个系统的性能与缓存利用率
- Plcache
- 基于缓存路的分区
- HybrCache
- 使用全关联映射和随机替换的方式,来将缓存路分配给受保护的域(或飞地)
- 克服基于way的分区方案的缓存未充分利用问题
- 仅将缓存资源的子集分配给受保护域,实现了更公平的缓存利用率,而不会严重降低整体系统性能。
- HybCache 无法在大型 LLC 上实际扩展,因为它会产生高功耗开销。
- HybCache 无法防御基于占用的攻击,因为它不强制执行严格的分区。
- HybrCache
与内存页面着色方案的比较
- 内存页面着色方案
- 在物理内存地址到缓存行的映射过程中,保证敏感应用所使用的缓存行不会重叠
- 缺点
- 对内存布局影响太大,不能完全支持DMA
- 需要修改操作系统或Hypervisor
- 静态分配缓存行,无法在运行时修改分配的缓存行的数量
- CHUNKED-CACHE的优势
- 可以支持比缓存路数量更多的保护域
- 支持共享内存并扩展到大型 LLC
- 不影响内存布局
- 与内存管理软件兼容
- 允许在运行时动态修改缓存块大小
与基于密码学随机化的防御的比较
- 基于密码学随机化的防御
- 早期使用庞大的随机映射表
- 之后依赖密码学源语来产生随机化的映射
- 时间安全缓存(Time Secure Cache)
- 使用缓存行地址和进程ID作为输入,经过keyed function计算索引
- 由于使用了low-entropy函数计算索引,导致必须频繁的重新求key和刷新缓存,增加了复杂性和性能开销
- 基于加密原语防御的缺点
- 这些防御仅与已知的最佳/最快攻击策略/最小逐出集构造算法一样安全,没有可靠的未来安全保证。
- 低延迟加密原语的不可预测性尚未得到充分研究。为此部署抗形式化密码分析的原语会增加延迟,进一步降低关键路径的性能
- 通过增加re-keying的频率来缓解新的攻击,会导致不切实际的性能开销
- CHUNKED-CACHE的优势
- 通过在执行域之间提供严格且可配置并可选择的分区,从根本上消除了不可靠性和不灵活性。
- 提供性能与安全性的权衡
- 每个域都能够分配所需的缓存容量,从而体验它选择相应地容忍的性能
- 能够经受住缓存侧信道攻击和其他攻击方法的考验,同时又不会牺牲性能
- 不会对操作系统带来过重的性能开销
讨论
-
Chunked-Cache如何防御来自HyperVisor的攻击?
Chunked-Cache使用TEE创建I-Domain进程,并使用TEE可信的配置自己运行时的元数据。TEE能防御恶意的高特权级代码(如操作系统和HyperVisor)窃取机密信息。
-
gem5模拟器与TEE之间是何种关系?
gem5是一个开源计算机架构模拟器,包括系统级架构以及处理器微架构。它为系统组件的模拟实现了大量模型,包括CPU、DRAM、片上互连、一致性缓存、I/O设备等。这些模型都是参数化的,并且可以针对不同的系统进行定制。例如:
- gem5具有对多个ISA的模块化支持,目前支持Arm、x86、MIPS、Power、RISC-V、SPARC等。所有这些ISA都可以与gem5的任何CPU模型一起使用。
- gem5包括四种不同的CPU模型。Simple CPU模型可用于内存系统研究,可以更快地模拟系统,但与真实CPU相比过于简单。此外,gem5包含详细的有序执行CPU (Minor CPU) 和乱序执行CPU (O3 CPU),虽然运行速度较慢,但可以提供更真实的结果。另外,gem5支持基于KVM的CPU模型,当主机ISA与gem5中运行的应用程序相同,它能绕过模拟并使用底层主机的处理器来运行gem5中运行的二进制文件,此时gem5上程序的运行速度和在主机上几乎相同。这主要可用于采样模拟以及快速前进到感兴趣区域和检查点位置。
- gem5中有两种不同的缓存系统:Ruby和Classic。当使用Ruby缓存时,用户还可以选择片上网络模型,包括简单的Simple模型和详细的Garnet模型。
这篇文章使用了在gem5上实现了Chunked-Cache的RTL模型,并用它扩展一个开源的RISC-V处理器。gem5支持RISC-V上的Keystone可信执行环境。
-
TEE是如何使用Cache的,在TEE初始化前,Chunked-Cache如何运作?
Chunked-Cache使用的CST与DCAT表为硬件实现,存储在Chunked-Cache内部。这些信息的更新会由TEE保护,仅能通过TEE可信地配置与更新。
I-Domain域与NI-Domain域的分配信息存储在TEE的保护区域中。
起初,Chunked-Cache初始状态为所有的Cache都能被操作系统使用,此时TEE也可以正常使用Cache。直到新的程序被设置为以I-Domain运行,TEE创建enclave运行该程序,并且更新Chunked-Cache中的CST与DCAT表,从而实现Chunked-Cache将缓存独占地分配给I-Domain使用。