FuzzGuard: Filtering out Unreachable Inputs in Directed Grey-box Fuzzing through Deep Learning
directed grey-box fuzzing (DGF).与基于覆盖的模糊测试(其目标是增加代码覆盖范围以触发更多错误)不同,DGF旨在检查一段潜在的错误代码(例如,字符串操作)是否确实包含错误。
本文提出了一种基于深度学习的方法来在执行目标程序之前预测输入的可达性(即是否错过目标),以帮助DGF筛选出无法到达的输入以提高模糊测试的性能。为了运用DGF进行深度学习,本文设计了一套新技术(例如,step-forwarding方法,代表性数据选择)来解决标签数据不平衡和训练过程中时间不足的问题。 此外,本文实现了提出的称为FuzzGuard的方法,并为其配备了最新的DGF(例如AFLGo)。 对45个实际漏洞的评估表明,FuzzGuard将vanilla AFLGo的模糊处理效率提高到了17.1倍。
Introduction
directed fuzzing 导向fuzz
模糊测试是一种自动程序测试技术,通常分为两类:基于覆盖率的模糊测试和导向模糊测试。 前者的目标是实现较高的代码覆盖率,希望触发更多崩溃。 导向模糊测试旨在检查给定的潜在错误代码是否确实包含错误。例如AFLGo,SemFuzz和Hawkeye,都是已有的导向fuzzer。
导向模糊测试(DGF)
众所周知,随机输入不太可能到达错误代码,更不用说触发错误了。 因此,大多数工具都会对目标程序进行插桩,以观察运行时信息并利用该信息生成可能到达错误代码的输入。
理想的DGF应该生成所有可以到达错误代码的输入。 不幸的是,在实际情况下,大量生成的输入可能会错过目标,特别是当buggy code嵌入受许多(例如数千个)约束的代码中时。面对这种情况,各种技术(例如,基于退火的Power Schedules)被设计为生成可到达的输入。 但是,即使对于最先进的DGF工具(例如AFLGo),无法访问的输入比例仍然很高。 根据本文使用AFLGo进行的评估,平均而言,超过91.7%的输入无法到达错误代码。
如此大量的无法到达的输入会在模糊测试过程中浪费大量时间。 理论上,传统的程序分析方法(例如符号执行)可以使用目标程序中所有分支的约束来推断输入的执行结果。 但是,解决约束所花费的时间将随着约束复杂性的增加而急剧增加。
Challenges
C1
Lack of balanced labeled data.训练深度学习模型需要均衡的标签数据,但是fuzzing过程中的输入是不平衡的。尤其是在模糊测试的早期,甚至没有可到达buggy code的输入。没有均衡的标记数据,训练后的模型将容易出现过拟合的情况。
C2
新生成的可达输入看起来可能与训练集中的可达输入完全不同,从而使训练后的模型无法预测新输入的可达性。新输入可能会通过以前从未见过的不同执行路径到达错误代码。 因此,仅沿一条执行路径使用输入来训练模型可能无法正确预测新输入的可达性。
C3
Efficiency。在训练传统模式识别模型的任务中,在训练上花费的时间没有严格限制。 但是,在模糊测试过程中,如果花费在训练模型和预测输入的可达性上的时间大于花费在执行有输入程序上的时间,那么进行预测是没有用的。
FuzzGuard
FuzzGuard分三个阶段工作:模型初始化,模型预测和模型更新。
- 在第一阶段,fuzzer生成各种输入,并使用它们运行目标程序,以检查是否触发了错误。 同时,FuzzGuard保存输入及其可达性,并使用标记的数据训练初始模型,该数据可能不平衡(C1)。 为了解决这个问题,本文设计了一种step-forward的方法:选择buggy code的主导者(称为“主导节点” )作为中间阶段目标,然后让执行首先到达主导节点 。 这样,就可以更早地获得平衡数据,以训练仅针对主导节点的模型,从而将执行时间降至最低。
-
在第二阶段中,在Fuzzer生成大量新输入之后,FuzzGuard利用该模型预测每个输入的可达性。 如C2中所述,训练后的模型可能不适用于新生成的输入。 为了解决这个问题,本文设计了一种有代表性的数据选择方法来对每一轮突变中的训练数据进行采样,从而最大程度地减少了采样数据的数量,从而提高了效率。
- 在第三阶段,FuzzGuard使用第二阶段收集的标记数据更新模型,以提高其准确性。本文通过谨慎选择更新时间来应对挑战C3。以前的模糊研究主要集中在生成各种输入,覆盖更多的代码行(CGF)或获取错误的代码(DGF)。 设计了输入上的各种变异策略。 相比之下,本文的研究并未直接对输入进行突变(本文依赖于当前的突变策略,例如AFLGo),而是筛选出无法到达的输入。 这样,DGF不需要使用无法到达的输入(肯定无法触发目标错误)来运行目标程序,从而提高了整体效率。
本文基于AFLGo(一个开源的DGF)实现了FuzzGuard。本文在获取到的性能和漏洞结果外,还发现fuzzer生成的输入越多,FuzzGuard的性能就越好。此外,如果目标节点更早达到平衡状态,则可以节省更多时间。
Motivation
当前的DGF旨在生成可能到达特定错误代码的输入,并进一步期望触发错误。在模糊测试过程中,很多输入最终都无法到达错误代码(不可能触发错误)。 根据本文的评估,平均超过91.7%的输入无法达到错误代码。如果存在一种足够快的方法来预测输入的可到达性,则fuzzing过程不需要使用不可达的输入来执行目标程序。 这样,可以提高模糊测试的整体性能。
受到深度学习在模式识别领域的最新成功的鼓舞,本文想探讨深度学习是否可以应用于识别(不)可达输入。
Methodology
Overview
本文提出了FuzzGuard的设计,这是一种基于深度学习的方法,可以帮助DGF过滤掉无法到达的输入,而无需真正执行目标程序。这样的数据驱动方法避免使用传统的耗时方法,如符号执行,以获得更好的性能。
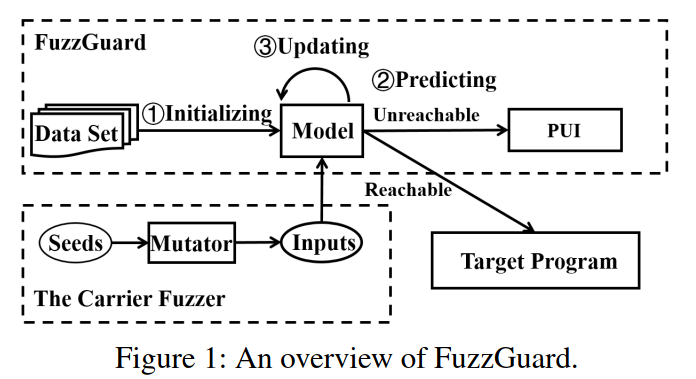
FuzzGuard包括三个主要阶段:模型初始化(MI)、模型预测(MP)和模型更新(MU)。它与DGF(称为”carrier fuzzer”)一起工作。
- MI阶段,carrier fuzzer生成大量输入并观察任何异常。FuzzGuard记录程序是否可以为每个输入执行目标错误代码。然后FuzzGuard利用输入及其可达性训练模型。
- MP阶段,FuzzGuard利用模型来预测新生成的输入的可达性。如果输入是可到达的,它将被输入到程序中进行实际执行。在这个过程中,FuzzGuard会观察输入是否能够真正到达目标代码。
- MU阶段,FuzzGuard通过增量学习进一步更新模型,以保持其效率并提高其性能。无法到达的输入将临时保存在”不可达输入池”(PUI)中,以便在模型更新后由更精确的模型进行进一步检查。
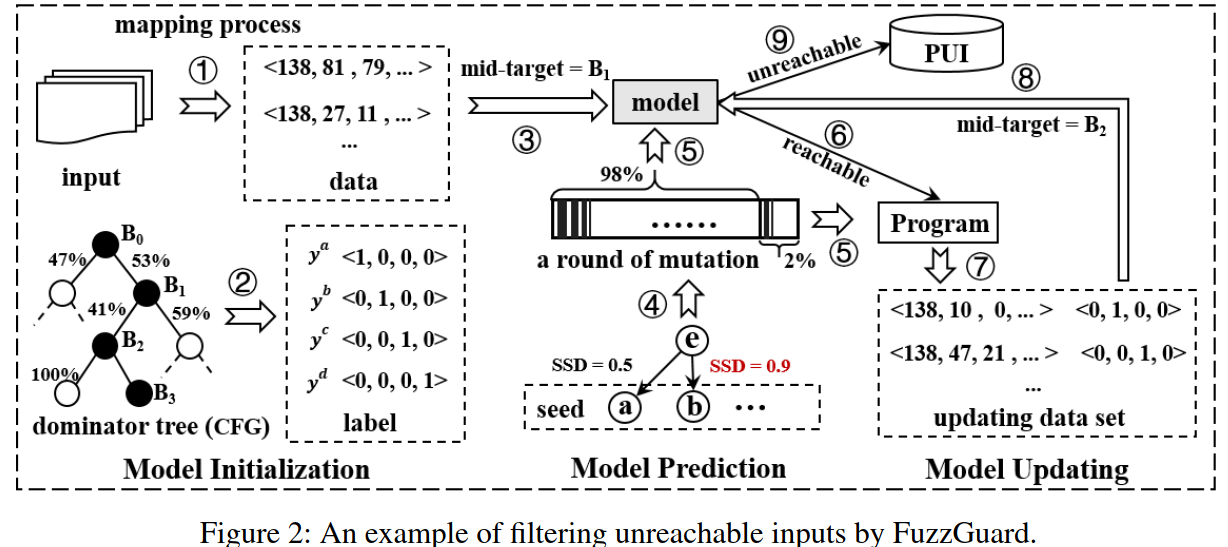
Model Initialization
但是,为每个前导节点训练一个模型花费的时间太长。 这主要是因为当FuzzGuard前进到下一个前导节点时,需要重新训练模型。 我们的想法是只为所有前导节点(包括buggy code本身)训练一个模型。
本文工作选择CNN,原因有2:
- CNN适合处理长数据
- 训练CNN模型花费时间比RNN短,适合fuzzing
本文选择使用3层CNN模型。第一层可以学习每个字节之间的关系,而其他两层则可以学习高维特征(例如,将多个字节组合成一个输入字段,并组合多个字段以影响程序执行)
通过这种方式,通过让carrier fuzzer运行一段时间以收集初始训练数据集。 在初始训练数据集达到平衡之后,模型可以学习到输入所有节点的可达性。 该模型的目标是学习目标函数$f$(即$y=f(x)$),其中包含许多卷积运算。 卷积操作使用许多过滤器从数据中提取特征: \(y_i=w^T x_i=\sum_{i-k<j<i+k}w_j\cdot x_j,i\in \{1,2,\cdots n-k\}\)
Prediction
模型初始化后,FuzzGuard利用模型预测每个输入的标签,并过滤掉那些不可达的输入。
对于输入x,假设模型只能预测$B_t$之间的前导节点,并且预测结果$y^p$ \(f'(y^p,t)= \left\{ \begin{aligned} reachable\qquad y^p_i=1\wedge i\ge t\\ unreachable\qquad y^p_i=1\wedge i< t \end{aligned} \right.\)
但是,在实际情况下,即使生成许多标记数据,预测结果依然不够准确。
主要原因是,即使新生成的输入可以达到目标,它们看起来也可能与训练集中的可到达输入完全不同。 这是可以理解的:这些输入可能来自不同的种子。
从同一种子变异而来的大多数输入彼此略有不同,而在从不同种子变异而来的输入之间可以发现许多差异。 因此,完全使用以前执行的输入可能无法训练非常准确的模型来预测新生成的输入的可达性。
为了解决这个问题,本文提出了一种代表性数据选择方法,该方法从每一轮突变中选择许多代表性输入以执行和训练。
本文将固定数量的输入(例如5%)作为该突变的代表数据,这些输入是从一轮突变中随机抽取的。
但是,不能直接通过两个种子的相似性,来假设两个输入集合的分布是相似的。 这主要是因为不同的突变策略(例如,位和字节翻转,简单的算术,堆叠的调整和拼接)可能会极大地改变种子,并使后代看起来完全不同。
本文想法是将种子与相应的突变策略一同进行比较。
如果两个种子相似且策略相同,考虑从组合集中选择较少的输入。
Model Updating
本文使用增量学习来训练一个动态模型。
更新策略:
- 当模型的假阳性率超过阈值时,更新模型
- 当到达新的前导节点时,更新模型
Implementation
MI
初始阶段,FuzzGuard只有在收集到足够的平衡的数据(或新数据)后才开始训练(或更新)模型。
DGF需要一个目标(潜在的)buggy code,其位置是Fuzzing已知的。为了设置buggy节点的前导节点,本文生成目标程序的调用图(CG)和控制流图(CFG),并设置前导节点。本文实现中使用NetworkX和LLVM生成的CG和CFG中自动寻找前导节点。
MP&MU
本文将SSD的$\theta _s$设置为0.85,并且每轮突变的默认采样率为5%。当SSD超过阈值时,采样率将降低到$(1-\theta _s)/5$(即小于3%)。根据本文评估,该取值可达到最佳性能。
考虑到不同程序的模型精度差异很大,本文根据之前的执行情况动态地改变$\theta f$:$\theta _f=1-acc{avg}$。$acc_{avg}$代表先前更新的模型的平均精度。
Model Implementation
对于模型训练,本文使用PyTorch实现CNN模型。
我不搞深度学习,这一块我就略过了
Deployment of FuzzGuard
为了实现数据共享,团队在AFLGo中的fl-fuzz.c中添加了一个函数Checker()。

Evaluation
本文实验结果表明,FuzzGuard比AFLGo提高了17.1倍的fuzzing性能。
Settings
本文选择了15个处理10种常见文件格式的真实程序,包括:
- 网络包(如PCAP)
- 视频(如MP4、SWF)
- 文本(如PDF、XML)
- 图像(如PNG、WEBP、JP2、TIFF)
- 压缩文件(如ZIP)
不幸的是,三个程序(mupdf、rzip、zziplib)无法编译,而两个程序(apache、nginx)没有给出漏洞的详细信息。
所以本文选择了剩下的10个作为目标程序,以及过去3年中对应的bug。
对于不同的输入格式,本文使用AFLGo提供的测试用例作为初始种子文件开始fuzzing(实验前提是相信AFLGo使用自己选择的初始种子文件将表现良好)。
所有的实验和测量都是在两台运行Ubuntu16.04的64位服务器上进行的,该服务器有16核(Intel(R)Xeon(R)CPU E5-2609 v4@1.70GHz)、64GB内存和3TB硬盘以及2个GPU(12GB Nvidia GPU TiTan X)和CUDA8.0。
Effectiveness
为了证明FuzzGuard的有效性,本文使用10个实际程序中的45个漏洞对安装了FuzzGuard的AFLGo和原来的AFLGo进行了评估。
对于配备FuzzGuard的AFLGo和vanilla AFLGo的理想比较是比较AFLGo的fuzzing时间($T_{AFLGo}$)和AFLGo配备FuzzGuard时的相应时间($T_{+FG}$)。但是实际上不能直接使用相同的种子输入来比较AFLGo和AFLGo+FuzzGuard的fuzzing过程,因为变异是随机的,所以两次fuzzing过程中的输入序列可能会差异很大。
本文想法是在两个不同的fuzzing过程中使生成的输入序列相同。特别是对于目标程序的漏洞,本文使用一个普通的AFLGo来执行fuzzing,并按顺序记录所有变异输入的序列,直到目标漏洞被触发(例如崩溃)或超时(本评估中为200小时)。 在此过程中,记录了fuzzing时间$T_{AFLGo}$。然后,使用相同的输入序列$I_{AFLGo}$来测试配备FuzzGuard的AFLGo,记录过滤后的输入(过滤后的输入数量为$n_{filtered}$,过滤后的输入与所有生成的输入的比率$filtered=N_{filtered}/N_{Inputs}$。 评估还记录了FuzzGuard($T_{FG}$)的时间成本,包括训练时间和预测时间。这样,就可以知道配备FuzzGuard的时间,并与$T_{AFLGo}$进行比较:
\[T_{+FG} = T_{AFLGo} − \sum_{i\in filtered}t_i +T_{FG}\]$I_{filtered}$ is the inputs filtered out by FuzzGuard
$t_i$ stands for the time spent on executing the target program with the input i
注意,$I_{AFLGo}$中的最后一个输入是AFLGo生成的第一个PoC或AFLGo在超时前生成的最后一个输入。
与FuzzGuard相比,在$I_{AFLGo}$中随机丢弃输入的方法将随机决定是否丢弃最后一个输入。评估结果表明FuzzGuard平均减少了65.1%的输入。如果通过随机方法丢弃相同数量的输入,最后一个输入(可能的PoC)也可能以65.1%的概率被丢弃。
相比之下,FuzzGuard的假阴性率为0.02%(后文有介绍)
Understanding the performance boost
- The earlier the model is trained, the more time could be saved
- The more reachable inputs generated by the carrier fuzzer, the less effective FuzzGuard is
Complicated Functions
评估中平均的唯一函数数和约束数分别为15.5万个和31.59万个,超过50%的bug由数千个约束保护。
对于这些bug,FuzzGuard实现了1.4~15.9倍的加速。对于一些由数百万个约束保护的bug,FuzzGuard实现了10倍以上的加速。
Cost
在对45个bug的评估中,在线模型的训练时间平均为60分钟,其中包括13.5%的数据收集时间、0.5%的数据嵌入时间和86%的训练过程时间。
花在训练上的时间只占fuzzer生成输入的6%(平均15小时)。
FuzzGuard平均花费的总时间为1.4小时,仅占fuzzing总时间的9.2%($T_{+FG}$)和AFLGo执行的fuzzing总时间的2.5%($T_{AFLGo}$)。
小结

从上图可以看出,目标程序的平均执行时间占fuzzing总时间的88%以上,这意味着FuzzGuard可以节省的fuzzing时间的平均上限约为88%。FuzzGuard的时间开销应该小于限制。
Accuracy
准确度取决于是否正确判断可达性。它的行为越精确,就可能过滤出更多无法访问的输入。
本文自称”不会遗漏任何PoC,因为过滤后的输入将保存在PUI中,PUI将由更新的模型进一步检查”,理论上不会产生误报。但是FuzzGuard设置了timeout,所以如果在时限内没有找到一个false negative input,那么它将会丢失。但是幸运的是,评估中的45个bug,由于准确模型,PUI中没有发现PoC。

从图中可以发现FuzzGuard非常准确(从92.5%到99.9%)。平均准确率为98.7%。所有漏洞的误报率平均为1.9%。
误报不会使PoC丢失。它们也不会增加执行输入所花费的时间。
漏报可忽略不计,平均为0.02%。只有4个漏洞有漏报,最高的是0.3%。
假阳性和假阴性的主要原因是缺乏平衡的代表性数据。例如,如果一个不可到达的输入与一个可到达的输入足够相似,那么它可以被FuzzGuard预测为可到达的。
假阴性可能会让程序通过以前从未见过的执行路径到达目标错误代码。如果这些新的执行路径能够被模型学习,那么预测将更加准确。
在评估中,经过长时间的fuzzing后,未发现的路径数会减少,这可能是导致误报率较低的原因。
Findings
在评估中,发现了23个未公开的bug(其中4个0-day)。
未公开的bug的bug代码实际上并不是本文的目标。FuzzGuard的目标是通过删除无法访问的输入来提高Fuzzing的效率,而不是触发新的bug。
Discussion
Benefit to input mutation
目前的fuzzer大多集中在对输入进行变异以提高fuzzing的性能。本文思路不同,本文想法是帮助DGF过滤掉无法到达的输入。
基于对FuzzGuard提取的特征的理解,本文发现FuzzGuard可以学习影响执行的字段。因此,FuzzGuard可以进一步帮助DGF进行输入变异。
Memory usage
理论上,可以将无法访问的输入永久保存在内存中,以避免丢失PoC。然而,在实际情况下,记忆是有限的。所以本文的想法是删除那些不可能到达buggy code的输入。
FuzzGuard+AFLGo发现的所有bug最终都可能被AFLGo发现。
笔记
- 实际误报、漏报存疑
- 图2中给的例子,这个前导节点看起来是唯一路径,但是实际上应该有多种路径到达某个buggy code,并且fuzzer应当是对全局进行fuzzing,这个标签会相当复杂,FuzzGuard是怎么管理这个标签和dominator tree的。它的策略不会是一个一个漏洞分析过去吧。
- 两个组成部分之间的通信是否会产生性能损耗以及通讯延迟
- effectiveness小结中的节省88%似乎过于理想。这个88%是针对原生AFLGo做的,FuzzGuard最完美的情况就是把所有程序执行都优化掉,所以上限只能达到88%。话是没错,但是这显然实现不了吧。
- FuzzGuard的目的是加速,即它的加速方式不是解决”会阻碍fuzzing进行的难题”,而是优化”fuzzing的无效操作”。问题就是,是否存在着一些漏洞,是当前使用的Fuzzer无论如何都解决不了的。或者说这些漏洞触发路径上存在障碍,对fuzzing时间的阻碍的数量级,远大于FuzzGuard缩减时间的数量级
组会问题记录
- 导向fuzzer如何高效、准确、无遗漏地确定目标位置以及生成控制流图
- 文中的深度学习模型是否可以采用更加先进的模型
- 文中的深度学习模型是否具有泛用性及可迁移性,针对不同的程序、不同的漏洞类型,是否能保持如同文中的有效性等
- FuzzGuard能应用到其他fuzzer上吗