PhantomCache: Obfuscating Cache Conflicts with Localized Randomization
Background
1. Cache
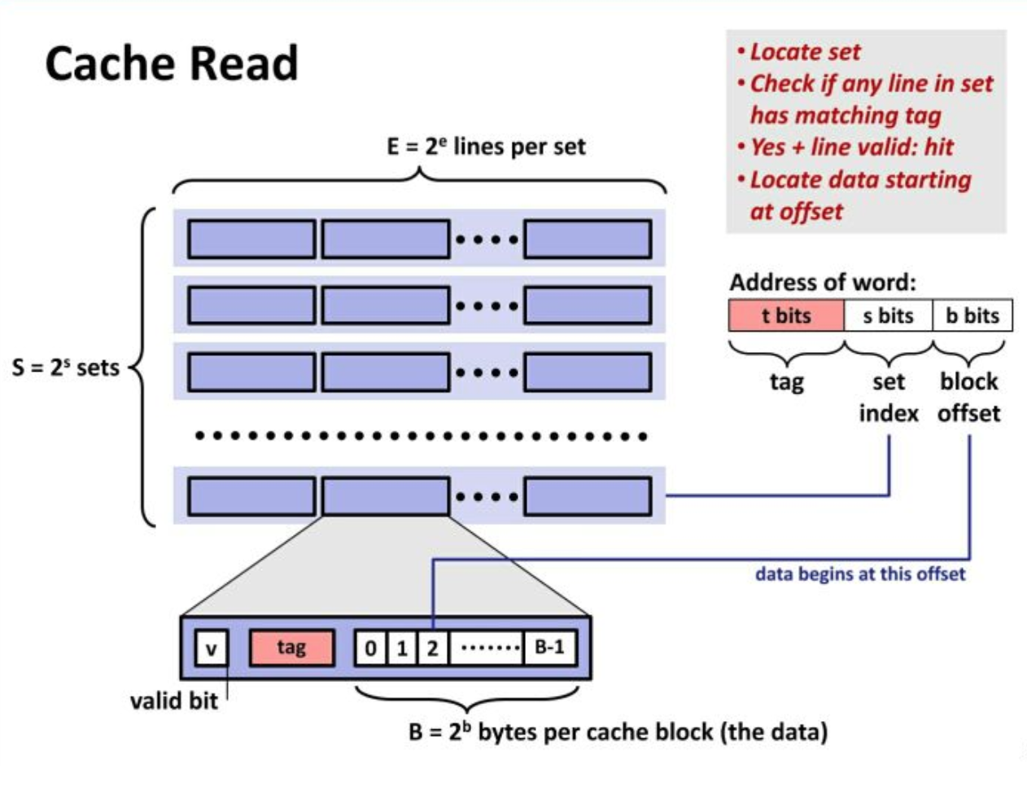
-
Cache line
每次内存和CPU缓存之间交换数据都是固定大小,cache line就表示这个固定的长度,通常为64 byte。
-
Cache set
一个或多个cache line组成cache set,也叫cache row
-
Bank
将cache分成多个小分区,可实现并行访问
-
内存地址映射到cache
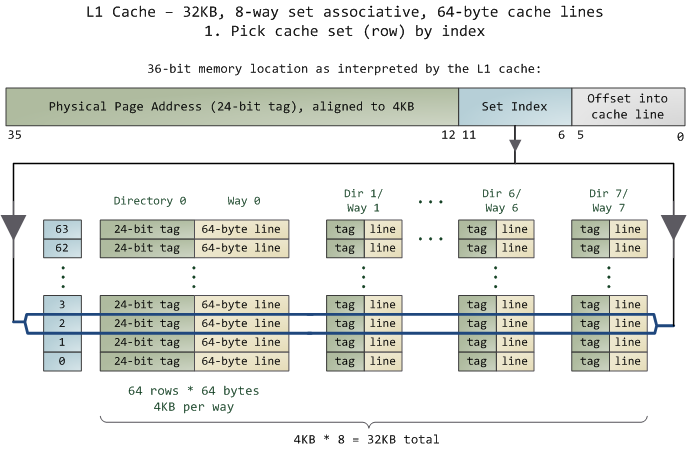
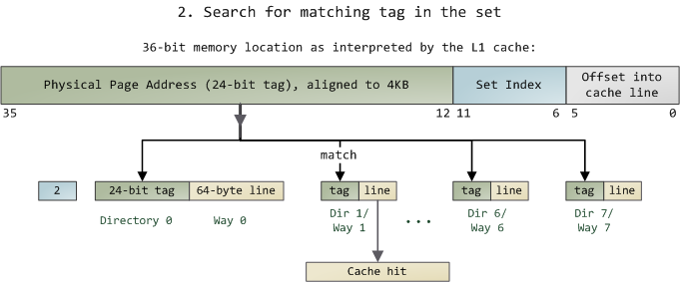
2. Conflict-based Cache Timing Attack
-
利用缓存冲突(cache conflict)来揭示进程的缓存访问行为
-
为了推断受害者是否已经访问了内存地址,攻击者需要构造另一个内存地址,使得该内存地址与目标内存地址映射到同一cache line。然后,攻击者会定期访问构造的地址。 第一次访问使相应的数据块被缓存。对于下一次访问,缓存命中(cache hit)表示未替换缓存的块,表明受害者没有在两次访问之间访问过感兴趣的内存地址。 否则,将发生高速缓存未命中(cache miss),并揭示受害者的内存访问行为。
-
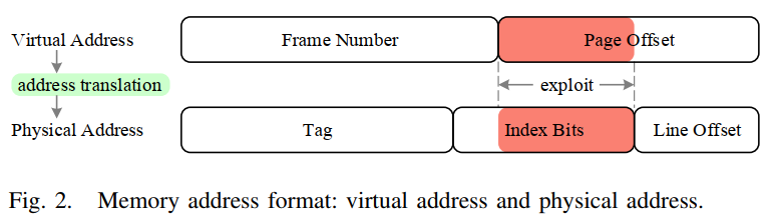
组相联机制——>只能知道内存地址映射到的cache——>驱逐集
-
Prime+Probe
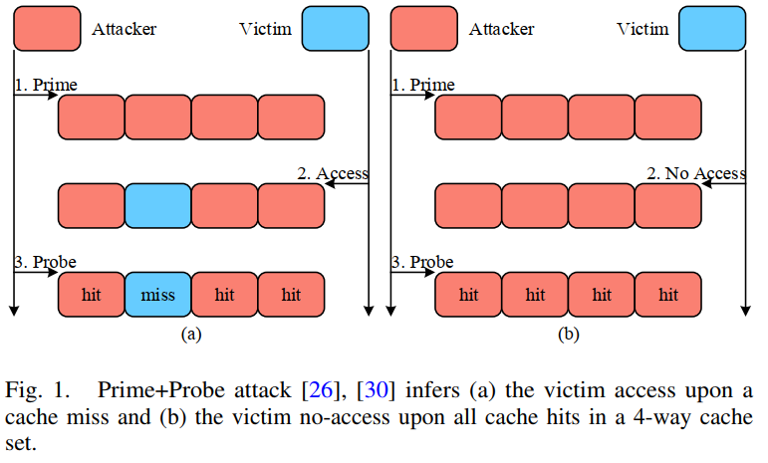
- Prime:攻击者用自己的数据来填充特定的或者是全部的Cache Set
- Wait:等待受害者进程运行并且访问受害者自己的数据
- Probe:攻击者再次去访问自己在Prime阶段装载进cache的数据
3. Minimal Eviction Set
- 最小驱逐集需具备两个属性:
- 相同映射:要求所有驱逐地址都映射到相同的cache set。如图1所示,如果某些驱逐地址映射到其他cache set,则即使受害者未访问示例cache set,它们也可能导致攻击者产生cache miss。这会导致Prime + Probe攻击失败。
- 最小基数:要求将驱逐地址的数量最小化到组相联数。小于组相联数的驱逐集基数不足以填满整个缓存集。如果驱逐集包含的地址超出了缓存集可以容纳的数量,则将导致它们自己之间的缓存冲突,并导致与受害者访问无关的cache miss。 这也使Prime + Probe攻击失败。
-
候选地址采样
-
为了采样初始候选地址,攻击者利用了现代处理器上的确定性内存到缓存映射策略:物理地址的索引位直接用作该地址映射到的cache set的索引。
-
可利用的是,虚拟地址及其对应的物理地址可以覆盖部分甚至全部索引位。
-
-
地址删除
-
主要思路:在每次迭代中,攻击者确定初始集合E中是否有候选地址e可以删除(Line 1-11)
-
地址e要满足的条件是:删除e不应使剩余的E不足以从缓存中逐出x。

-
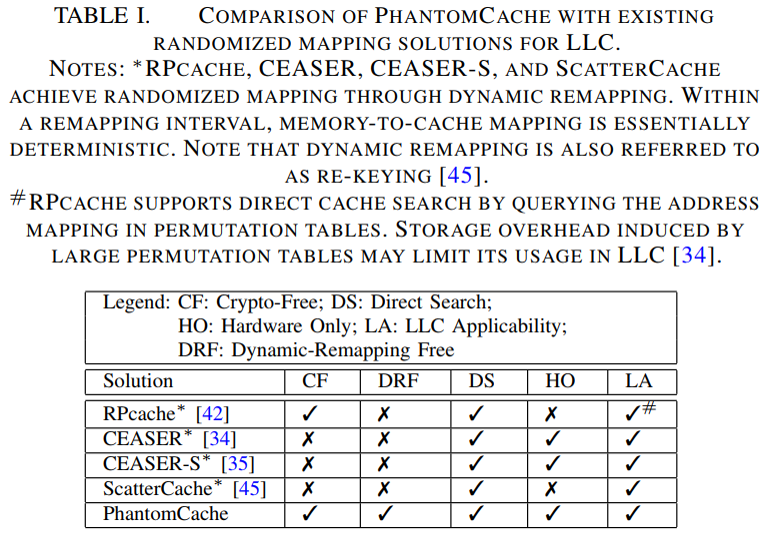
4. (Inefficient) Randomized Mapping for LLC
- 现有的针对conflict-based cache timing attack的对策存在缺点
- 基于检测的解决方案:通常基于阈值,容易受到false negatives的影响
- 缓存分区和模糊时间:降低缓存空间利用率和正常进程的时间测量,影响系统功能
- 随机映射是针对conflict-based cache timing attack的基本对策
- 随机映射旨在通过将内存块随机映射到缓存位置来打破确定性缓存冲突
- 此方法不会减少缓存冲突,但它提高了观察和利用缓存冲突的难度。 一旦放置策略随机化,任何地址的内存到cache映射就不会固定。在这种情况下,攻击者几乎无法找到和利用可能与受害者地址冲突的地址。
- 目前已经对小型L1缓存上的有效随机映射进行了充分研究,但它仍需要在更大的最后一级缓存(LLC)上的有效实现
-
间接随机映射保证快速查找可能随机映射到大型LLC中任何位置的块
-
间接随机映射:首先引入隐式映射,以延长找到冲突地址的时间。然后进行动态重映射以不时改变映射策略,从而带来随机性。
-
具有线性复杂度的最新攻击算法——>需要非常频繁的重映射——>增加未命中率和访问时延,较大的性能开销
-
最新基于skewed cache的设计——>一个地址可能的映射位置数仅等于未分区缓存中的一个cache set中的cache line数——>仍然需要低效的动态重映射
-
Overview
1. PhantomCache
- PhantomCache用于在没有动态重映射的情况下防御conflicted-based cache timing attack(本质:增加构建最小驱逐集的难度,同时减少性能开销)
-
利用局部随机化技术将随机化空间限制在缓存位置的较小范围内, 每次内存块进入高速缓存时,它都会随机放置在固定映射范围之外的位置。
-
局部随机化的实现:两个阶段的随机性
-
首先,对于每个地址,为它随机选择预定义数量的候选集,选择使用地址和随机映射函数来计算cache set索引。
-
其次,随机选择一个候选集来映射地址。
-
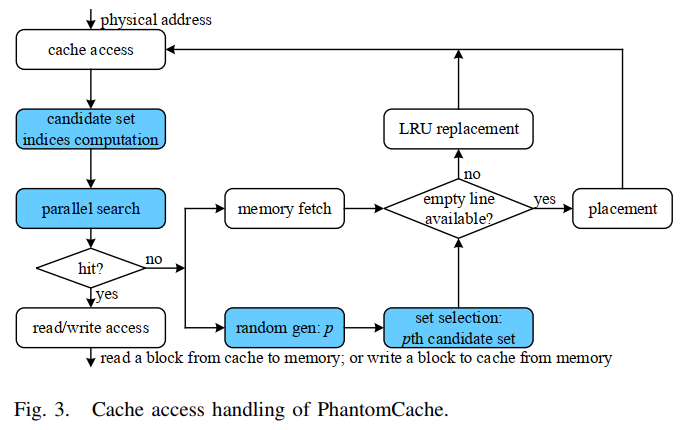
放置策略:PhantomCache将一个块放入多个候选集中随机选择的缓存集中。候选集的索引是使用块的地址和随机盐计算出来的。 给定要使用的r个候选缓存集,为缓存配置引入了r个随机盐。在机器启动时,使用片上伪随机数生成(PRNG)初始化这些随机盐。地址的候选集索引计算为(2),然后仅随机选择一个候选集进行放置(3),其中PRNG(r)生成一个从0到r−1的随机数。
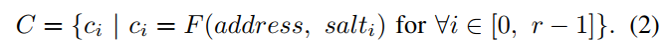
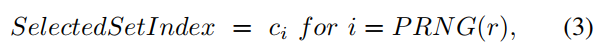
- 搜索策略:PhantomCache需要在其所有候选集中搜索一个块。 请求缓存访问后,首先通过公式2计算所有候选集的索引。然后,将地址的标记字段与每个集合中缓存的标记字段进行比较。匹配表示cache hit。否则,将发生cache miss,此时CPU需要从内存中获取该块并将其放置在缓存中。由于少量候选集足以保证安全性,因此在硬件中实现并行搜索是可行的,并且可以使用multi-banked缓存来改善并行性。
- 替换策略:PhantomCache不会对替换策略进行任何修改。将一个块放入一个缓存集中时,如果没有可用的缓存行,则需要替换一个缓存的块。 PhantomCache仅遵循所使用的替换策略,例如常用的LRU策略。
-
-
Design
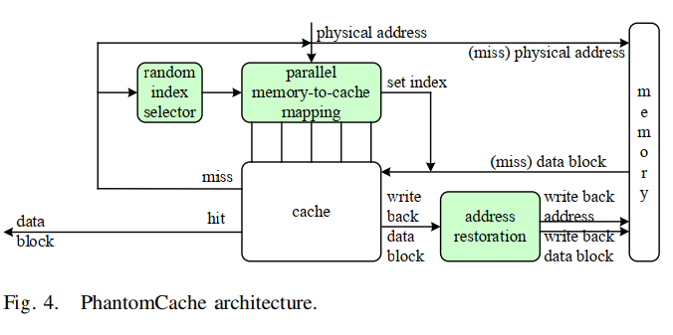
1. PhantomCache的具体实现
- 挑战:如何在实现局部随机化的同时优化额外的访问延迟
- 架构:局部随机化
- 内存到cache的映射
- 单时钟周期哈希
- Cache访问
- 并行搜索
- 地址恢复
2. 细节
- 内存到cache的映射(局部随机化的实现)
- 候选集索引的计算:使用地址的标记和索引位以及r个盐来计算,用随机选择器选择r个候选集之一进行放置
- 随机盐的生成:现代CPU上的快速内置硬件随机数生成器(HRNG),这些随机数存储在硬件的随机数池中,可直接从随机数池中请求r个随机数,避免了根据请求生成随机数的时间延迟
- r的大小(候选集的个数):一方面,考虑当r=1时的极端情况,PhantomCache退化为易受conflict-based cache timing attack的确定性映射。另一方面,较大的r由于在每个数据访问的所有r个候选集之间进行搜索,会导致较高的性能开销。经过实验分析,取r=8(在安全评估部分)。
- 内存到cache的映射(优化缓存开销)
- 优化缓存开销:本来,由于使用地址的标记和索引位以及盐来计算缓存集索引,需要将标记和索引位存储在cache line中。但是基于事实,具有相同索引位(或标签)的地址必须具有不同的标签(或索引位),可以不缓存索引位,将标记位和索引位分别输入到映射函数中。将缓存开销最小化到每个cache line仅
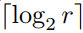 位随机数(0.50%的存储开销)
位随机数(0.50%的存储开销) 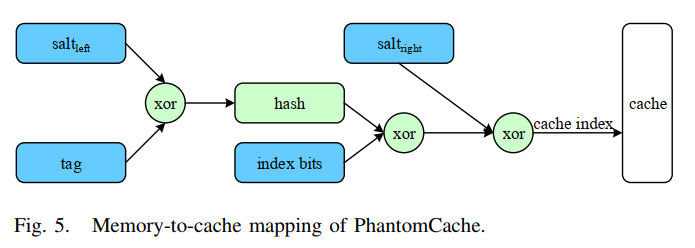
- 优化缓存开销:本来,由于使用地址的标记和索引位以及盐来计算缓存集索引,需要将标记和索引位存储在cache line中。但是基于事实,具有相同索引位(或标签)的地址必须具有不同的标签(或索引位),可以不缓存索引位,将标记位和索引位分别输入到映射函数中。将缓存开销最小化到每个cache line仅
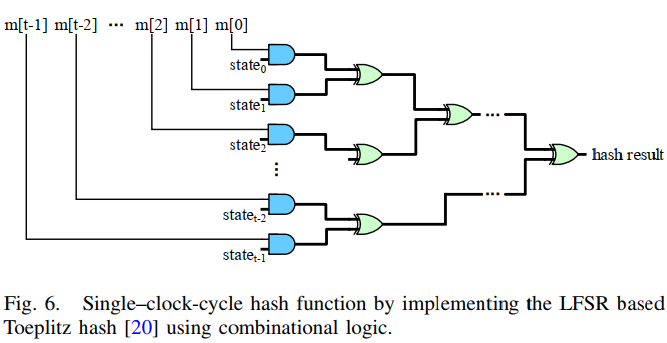
- 单时钟周期哈希
- 哈希函数需满足:较高的硬件效率,强随机性
- 基于LFSR的Toeplitz哈希:满足要求,但其实现使用顺序逻辑,消息需要一点一点地处理,如果消息很长,则会导致高延迟。
- 改进:使用组合逻辑将基于LFSR的Toeplitz哈希调整为单时钟周期哈希函数,状态值在引导时被预先计算并存储在寄存器中,可直接输入到哈希电路,而无需在每次哈希计算时重新生成导致延迟。

- 哈希函数用到的组合逻辑电路:1个AND门和6个XOR门
- 单个时钟周期可完成
- 性能下降为1.34%(时钟频率极高的处理器中)
- Cache访问
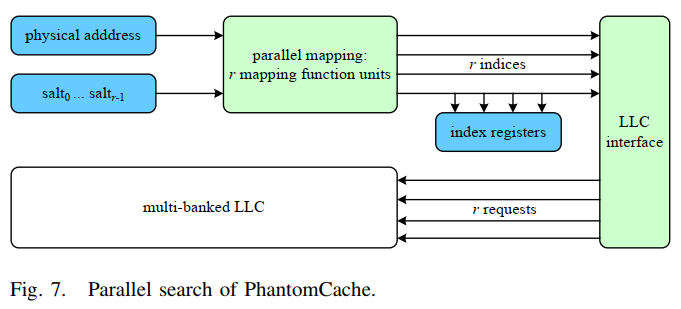
- Cache访问:请求访问cache后,PhantomCache会在请求地址的所有r个候选集合上强制进行并行搜索
- 计算候选集的所有索引,将其存储在索引寄存器,可直接生成一个随机数从中选择,无需重新计算索引,避免开销
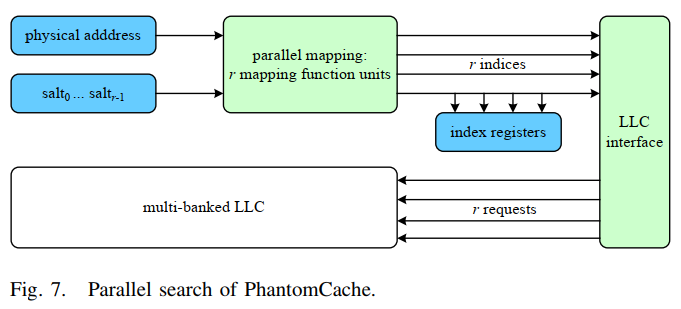
- 并行搜索:Multi-banked cache实现并行搜索
- Multi-banked cache:仅分成几个bank(如8个)LLC架构,其中每个bank包含相等数量的cache set
- 修改了LLC队列管理策略:将每个地址请求膨胀为r个请求,为LLC队列中的每个原始请求维护一个计数器和一个命中指示器
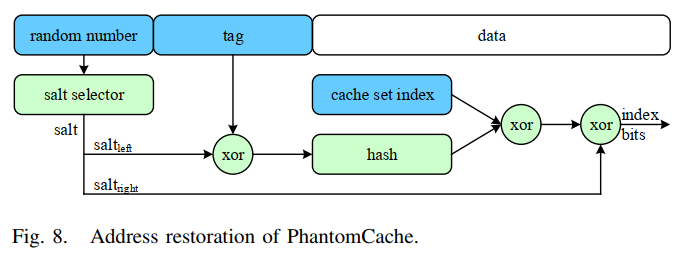
- 地址恢复
- 地址恢复:从cache写回内存时,需要恢复内存块的内存地址(如发生cache替换或进程终止后从cache中清除脏块时)
- 图5的逆过程
Security
1. 威胁模型
- 攻击者知道受害者进程访问的确切物理地址
-
攻击者拥有丰富的初始地址,其中包含足够的地址以形成最小驱逐集。它可以选择运行经典的O( E 2)算法或最新的O( E )算法 - 攻击者可以进行内存访问并测量访问延迟
- 攻击者在攻击过程中不会受到任何干扰,即它是唯一可以进行内存访问的实体,直到找到最小驱逐集为止。
- 关于PhantomCache的详细信息,攻击者可以了解映射函数(例如哈希函数)的设计。但是,它无法知道用于计算地址的确切缓存集索引的确切盐。攻击者可能会尝试将盐破解。
2. 原型实现
- 使用基于trace的微体系结构模拟器ChampSim实现PhantomCache
- 关键组件包括cache set索引计算单元、缓存搜索单元和缓存替换单元
- 支持包容性缓存(inclusive cache):添加了back_invalidate函数,并在缓存模块中修改了handle_fill和handle_writeback过程。替换数据块后,将调用back_invalidate来驱逐更高级别高速缓存中的数据块(如果其中存在)。
- 保持L2-LLC和LLC-内存的通信接口完整:修改了LLC模块内部的读取和写入过程中关于缓存搜索和缓存替换的处理。
- 对于搜索过程,添加了单时钟周期哈希函数,并在get_set函数中对其进行了调用。该函数返回一组候选集的索引,而不是由所请求地址的索引位确定的单个集合索引。为了对所有这些候选集执行缓存搜索和无效化,还修改了check_hit和invalidate_entry函数。
- Cache miss通过随机选择候选集之一来触发替换过程,然后将从内存中获取的数据块放置在LRU之后的所选缓存中。
3. 安全目标
- 总目标:防止攻击者在合理的时间内找到最小驱逐集
- 子目标:
- 驱逐地址的稀缺性。攻击者必须有足够的驱逐地址才能形成最小的驱逐集。
- 构造最小驱逐集的困难程度。几乎无法防止最小驱逐集的存在,所以需要阻碍构造最小驱逐集的过程(测试地址删除过程)。
- Crack salt的困难程度。如果攻击者知道这些盐,则可以极大地简化构造最小驱逐集的过程。
4. 安全目标实现
- 安全目标1——Scarcity of Fully-Congruent Addresses
-
Fully-congruent address:候选集完全相同的地址
-
当r足够大时,攻击者将永远找不到足够的完全一致的地址,因为它们不存在于可用内存空间中
-
假定最大存储空间为M,cache组相联性为m,PhantomCache的维度为r,cache line中的数据容量为c,并且cache set数量为s。保证完全一致地址稀缺的最小值r是满足以下约束的最小值r:
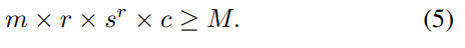
- 安全目标2——Hardness of Eviction Set Minimization
-
攻击者需要从大量地址开始,并设法将其最小化为最小驱逐集
-
Phantom增加了测试移除某一地址的难度:
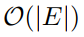 ——>变为
——>变为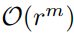
-
内存访问次数:
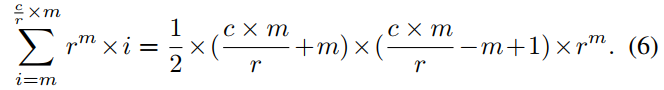

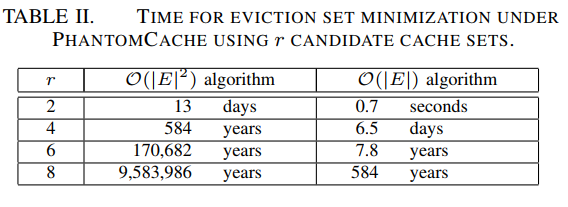
- 安全目标3——Hardness of Salt Cracking
- 盐的保密性决定了攻击者能否绕过最小驱逐集的构造过程,因此盐需具备抗暴力破解的能力
- 暴力破解的难度:
- 盐的长度:
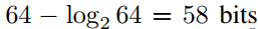
- 测试次数:
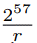
- 暴力破解盐所需的内存访问次数:
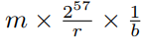
- 盐的长度:
Evaluation
-
实验设置
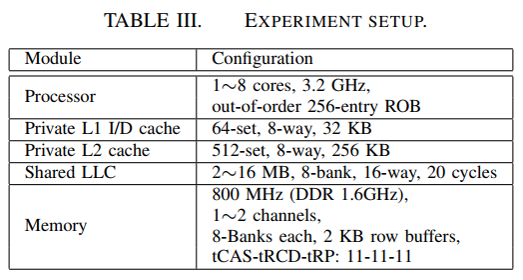
- Workloads
- SPEC CPU 2017 benchmark package中的工作负载
- 使用SPECspeed 2017 Integer和SPECspeed 2017 Floating Point套件中的所有20个基准
- 当在多核CPU上运行仅包含单个基准的工作负载时,每个核都在运行相同的基准
- 使用混合工作负载评估性能
- Metrics
- 每个时钟周期的指令数(IPC)( 高——>性能好 )
- LLC的每1000条指令的未命中率(MPKI)( 低——>性能好 )
- LLC的未命中率( 低——>性能好 )
- Results
-
结果表明,为了保护8-bank 16 MB 16路 LLC免受强大的O( E )攻击,PhantomCache在所有20个SPEC CPU 2017基准测试中平均降低了1.20%。 - 当考虑到与最新的ScatterCache [45]相同的17个基准时,PhantomCache平均只会降低1.06%的速度,效率是ScatterCache的2倍。在混合工作负载方面,PhantomCache带来的平均速度要小得多,仅为0.50%。
-
-
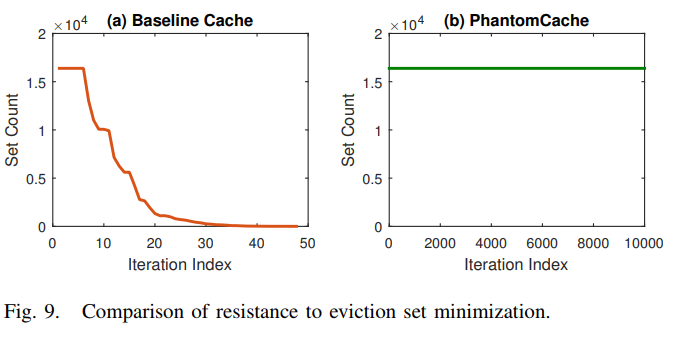
Resistance to Eviction Set Minimization
-
16 MB 16-way LLC with 16,384 cache sets
-
初始驱逐集的地址数:16,384 × 16
-
O( E )复杂度的最小驱逐集算法: -
传统cache:48次迭代
- Phantom:1000轮迭代仍找不到
-
-
- Processor Capacity
- 处理器容量的主要差异在于:内核数,LLC的大小以及连接到内存的通道数
- 考虑单核和多核处理器
- 结果:
- 归一化IPC下降平均值: 0.05%(1-core), 1.02%(4-core), 1.20%(8-core)
- 归一化MPKI上升:0.08%(1-core), 0.14% (4-core), 0.41%(8-core)
- 归一化miss rate:缓慢上升到1.40%
-
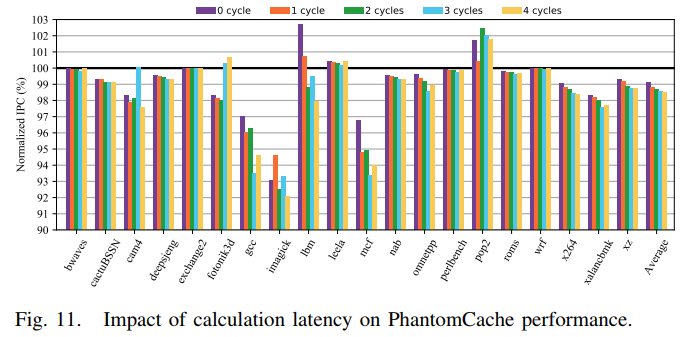
Calculation Latency
- 结果:
- 计算延迟范围为0到4个周期
- 4个周期的延迟使归一化IPC降低1.53%
- 较低的延迟会产生更好的性能,PhantomCache仅导致一个时钟周期的延迟,这仅将归一化IPC降低了1.20%
- 结果:
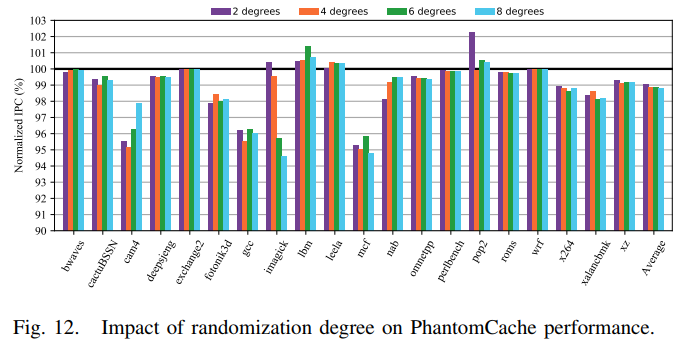
- Randomization Degree
- 结果:性能对随机化程度相对不敏感
-
LLC Capacity
- 结果:
- 在较大的LLC上,工作负载的性能更好。这是因为较大的高速缓存可保证较少的内存访问,这比高速缓存访问慢得多。
- 与基准缓存相比,PhantomCache使用8 MB,16 MB,32 MB和64 MB LLC的平均性能下降最多为1.20%。这表明PhantomCache可以有效地保护大型LLC免受conflict-based cache timing attack
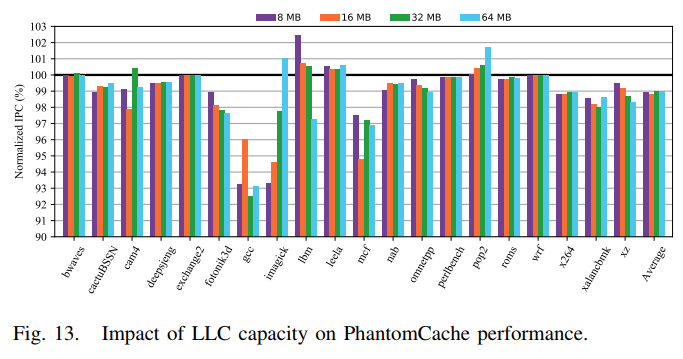
- 结果:
-
Bank Number
- 结果:
- 通常,性能下降会随着bank数量的增加而减少。
- 对于no bank的PhantomCache,平均性能下降在2.27%以内。
- 对于8 bank PhantomCache,平均性能下降仅为1.20%。
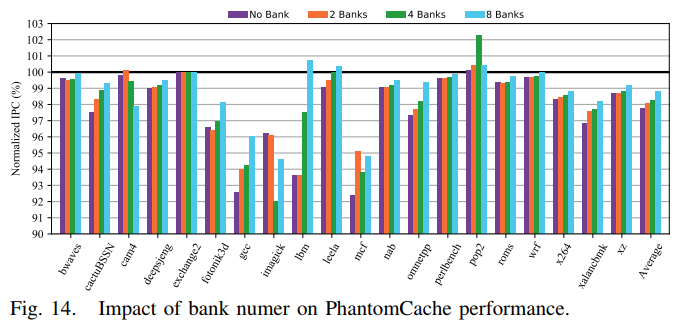
- 结果:
Discussion
①由于盐是存储在硬件的随机数池里面,这类随机数池存在一个问题,使用压力测试将这些盐用完后,系统会出现异常,进入异常处理的机制,此时会存在安全性问题。盐的使用过程经过了哪些地方,这些地方能否通过硬件产生的变化揭示出来。盐可否用侧信道得到?
②目前该防御方案只在模拟器上实现,那么如果应用到真实的处理器上实现,实际使用效果如何?整个处理器cache的亲和性,多线程情况下怎么访问同一数据块?
③从这篇论文的切入点出发,怎么找到侧信道攻击与防御的新思路?
老师的建议:
a. 目前聚焦的点还比较窄,仅局限于cache中,可以将侧信道的探索范围扩大,如网络、存储等;
b. 需要做实验来对一些攻击细节达到更深入的掌握;
c. 可将侧信道与新技术融合,如传感性、共享wifi、物联网设备等;
d. 可以更多去关注研究工作的现实价值,而不仅是在模拟器上实验;
e. 如构造硬件木马,使得在特殊条件下才激活,用于身份识别,在软件上是否可以尝试构造类似的代码;
f. 在其他设备上是否也存在像处理器中的cache一样的东西,如软件缓存、设备缓存,那么可以尝试用类似cache的方法去攻击这些部件,去做偏应用的工作。