Cache Telepathy: Leveraging Shared Resource Attacks to Learn DNN Architectures
Background
1. 为什么要获取DNN架构?
- 云服务商提供DNN给用户使用,DNN的架构决定了DNN的准确度和性能,获取DNN的架构具有很高的商业价值
- 一旦知道DNN架构,可以发起其他攻击,如模型提取攻击(获得DNN边的权重)和成员推理攻击(获知一个输入是否被用于训练DNN)
2. 面临的挑战
- DNN有大量的超参数,暴力破解不可行,即搜索空间巨大
- DNN的设计空间随着时间增长,使其更加复杂难以攻击
3. Deep Neural Networks
- 深度神经网络(DNN)是一类使用级联的多层非线性处理单元进行特征提取和转换的机器学习(ML)算法,常用的有全连接神经网络(或多层感知器)和卷积神经网络(CNN)。
- DNN架构
- 层的总数
- 层的类型,如全连接,卷积层或池化层
- 层间的连接,sequential and nonsequential connections
- 每一层的超参数,全连接层:那一层的神经元数量;卷积层:filter的数量,filter的大小,stride size
- 每一层的激活函数,如relu,sigmoid
-
DNN权重
每个DNN层中的计算都涉及输入神经元上的许多乘法累加运算(MACC)。 DNN权重(也称为参数)为这些乘加运算指定操作数。 在完全连接的层中,神经元的每个边都是具有权重的MACC; 在卷积层中,每个过滤器都是权重的多维数组,该数组用作计算输入神经元上的点积的滑动窗口。
- DNN使用
- 训练:DNN设计人员从网络体系结构和一组带有标签的输入的训练开始,然后尝试找到DNN权重以最大程度地减少错误预测误差。训练通常是在GPU上离线进行的,并且需要相对较长的时间才能完成,通常需要数小时或数天的时间。
- 推理:训练后的模型将被部署并用于对新输入进行实时预测。 为了获得良好的响应能力,通常在CPU上进行推理。
4. Prior Privacy Attacks Need the DNN Architecture(为什么获知DNN架构很重要?)
-
Model extraction attack
在模型提取攻击中,攻击者试图获得一个与oracle网络足够近的网络。 它假定攻击者从一开始就了解oracle DNN体系结构,并尝试估计oracle网络的权重。 攻击者创建一个综合数据集,从oracle网络请求分类结果,并使用这些结果来训练使用oracle体系结构的网络。
-
Membership inference attack
成员推断攻击的目的是推断oracle训练数据集的组成,表示为训练集中是否存在数据样本的概率。此攻击还需要oracle DNN体系结构的知识。 攻击者创建多个合成数据集并训练使用Oracle体系结构的多个网络。 然后,他们在这些网络上运行推理算法,其中一些输入在其训练集中,而有些不在训练集中。然后,他们比较结果以在训练集中的数据输出中找到模式。模式信息用于推断oracle训练集的组成。具体来说,给定一个数据样本,他们运行oracle网络的推理算法,获取输出并检查输出是否与之前获得的模式匹配。输出与模式匹配得越多,oracle训练集中的数据样本就越有可能存在。
-
Hyper-parameter staling attack
超参数窃取攻击窃取了ML算法中使用的损失函数和正则化项,包括DNN训练和推理。这种攻击还依赖于了解oracle DNN架构。 在攻击过程中,攻击者利用模型提取攻击来学习DNN的权重。然后,他们找到了使训练错误预测误差最小的损失函数。
5. Cache Telepathy’s Role in Existing DNN Attacks
- 获得了候选的DNN结构,缩小了搜索空间
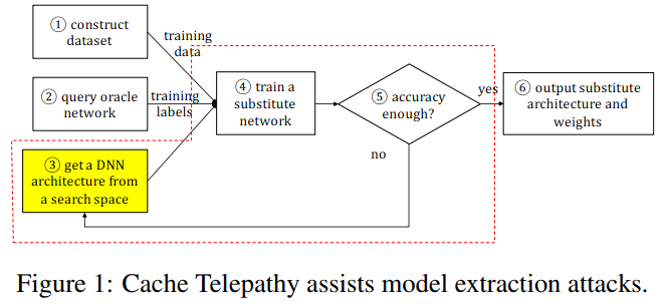
Overview
1. 威胁模型
- 黑盒访问:攻击者只可以通过官方的请求接口来访问DNN模型,攻击者先前不知道任何关于DNN的信息,包括超参数、权重和训练数据等。
- 共驻:攻击者进程与运行DNN推理的受害者进程共驻在同一处理器
- 代码分析:假设攻击者可以分析受害者使用的ML框架代码和线性代数库
2. 攻击原理(两点观察)
- DNN推理在很大程度上依赖于切片化的GEMM(通用矩阵乘法),而DNN的架构参数决定了GEMM调用的数量和在GEMM函数中使用的矩阵维度。
- GEMM算法易受cache侧信道攻击,因为它们会通过矩阵块来根据cache级别调整(平铺),当块大小是公开的,则攻击者可用cache侧信道攻击知道块的数量和矩阵大小。
3. 攻击步骤
- 第一步:cache攻击去监控矩阵乘法和获得矩阵参数
- 第二步:基于DNN超参数和矩阵参数之间的映射对DNN架构逆向工程
- 第三步:修剪剩余的未被发现的超参数的可能值,并为目标DNN架构生成修剪后的搜索空间
Detail
1. Analysis of DNN Layers
-
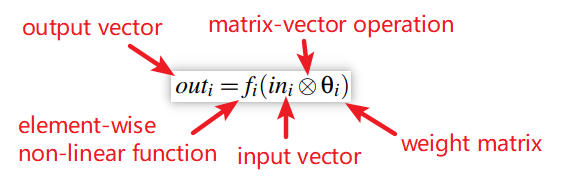
全连接层:前馈计算
-
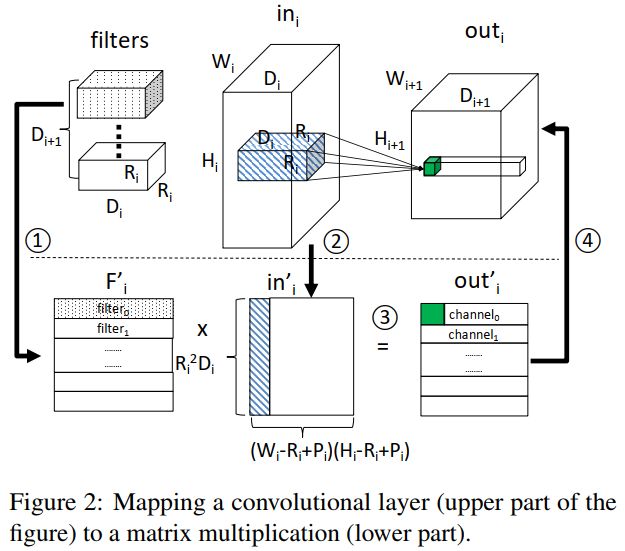
卷积层:卷积计算



2. Resolving DNN Hyper-parameters
-
Fully-connected Networks
-
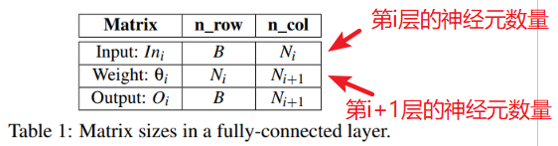
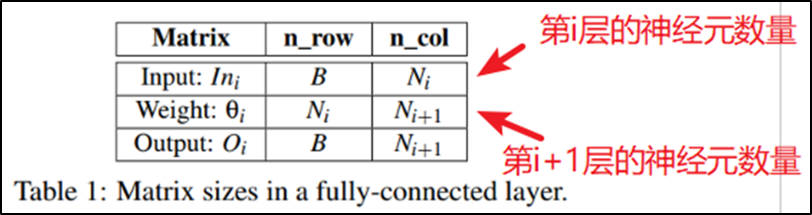
前馈计算在每一层执行一次矩阵乘法(Table 3的第1行)
-
第i层的神经元数量等于该层的权重矩阵的行数(Table 3的第2行)

-
-
Convolutional Networks
卷积网络通常由四种类型的层组成:卷积,Relu,池化和完全连接。每个卷积层都包含一批(B)矩阵乘法。 此外,对应于同一层的B个矩阵乘法始终具有相同的维度大小并连续执行。因此,可以计算具有相同计算模式的连续矩阵乘法的数量来确定B。


3. Connections Between Layers
-
Mapping Sequential Connections
-
顺序连接:两个连续的层之间的连接,第i层的输出作为第i+1层的输入。
-
首先,由于filter的宽度和高度必须是整数值,因此连续层中输入和输出矩阵的行数受到限制。根据table 3,如果连接了第i层和第i+1层,则第i+1层的输入矩阵中的行数
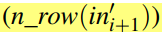 必须为 第i层的输出矩阵中的行数
必须为 第i层的输出矩阵中的行数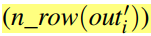 与整数平方的乘积。
与整数平方的乘积。
-
其次,由于池大小和跨步大小是整数值,因此在连续层之间的输入和输出矩阵大小的列数上还有另一个限制。如果连接了第i层和第i+1层,则第i层的输出矩阵中的列数
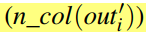 必须非常接近第i+1层的输入矩阵中的列数
必须非常接近第i+1层的输入矩阵中的列数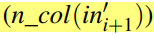 和整数平方的乘积。
和整数平方的乘积。 -
这两个限制可以用于区分顺序和非顺序连接。

-
-
Mapping Non-sequential Connections
- 非顺序连接:在给定两个连续的层i和i+1的情况下,存在第三层j,其输出与第i层的输出合并,合并后的结果用作第i+1层的输入。将从j层到i+1层的额外连接称为shortcut,其中j层是source层,而i+1层是sink层。Shortcut连接可以映射到GEMM执行。
- 首先,连续的GEMM之间存在一定的延迟,称为GEMM间延迟。非顺序连接中的sink层之前的inter-GEMM延迟比顺序连接中的延迟更长。原因是:在两个连续的GEMM之间执行的操作,对前一个GEMM输出的后处理(例如,批量归一化)和对下一个GEMM输入的预处理(例如,填充和跨步)。如果没有shortcut,GEMM间的延迟就与上一层输出大小和下一层输入大小之和成线性关系。但是,shortcut需要额外的合并操作,这会导致GEMM调用之间的额外延迟。
- 其次,shortcut的source层必须具有与非顺序连接的其他source层相同的输出维度。例如,当shortcut连接第j层和第i+1层时,第j层和第i层的输出矩阵必须具有相同数量的行和列。 这是因为这样才能合并维度匹配的两个输出。
- 这两个特性可以帮助辨别shortcut的存在,它的source层和它的sink 层。
4. Activation Functions
- 卷积层和全连接层是通过逐元素的非线性函数(例如relu,Sigmoid和tanh)进行后处理的,这些函数不会出现在GEMM参数中。
- 可以通过监控非线性函数是否访问标准数学库libm来区分Sigmoid和tanh的relu激活。 relu是一个简单的激活,不需要libm的支持,而其他函数则需要大量计算,通常利用libm来实现高性能。
- 本文认为几乎所有的卷积层都使用relu或者是相似的变种。
Experiment
1. Analyzing GEMM from OpenBLAS
-
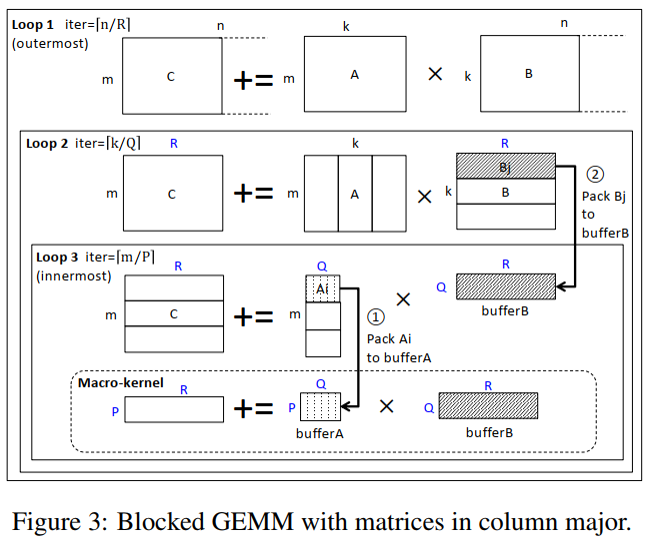
gemm_nn函数:执行分块矩阵乘法,实现的是Goto’s algorithm,该算法被现代多级cache所优化

-
A:m×k;B:k ×n;C:m×n ;目标:提取m,n,k
-
底部的Macro-kernel执行基本操作,将矩阵A中的P×Q块与矩阵B中的Q×R块相乘。该内核通常用汇编代码编写,并考虑CPU管线结构和寄存器可用性进行优化。选取块大小,以使A的P×Q块适合L2 cache,B的Q×R块适合L3 cache。
-
三层循环嵌套;将循环迭代的次数标记为:iter3,iter2,iter1;各值为:


-
Loop 3分成两个部分:第1部分执行第一次迭代,第2部分执行剩下的。
- Loop 3的第一次迭代(Line 3-7): Line 3:使用itcopy函数将来自矩阵A的P×Q块中的数据打包到一个缓冲区(bufferA)中。(对应于图3的1) Line 5:使用oncopy函数将来自矩阵B的Q×R块中的数据打包到一个缓冲区(bufferB)中。(对应于图3的2)以Q×3UNROLL子块为单位复制来自矩阵B的Q×R块。这会将Loop 3的第一次迭代分解为一个循环,标记为Loop 4。 Line 6:macro-kernel(函数kernel)在两个缓冲区上执行。
- Loop 3 的剩余迭代(Line8-11): 跳过上述的第二步,这些迭代仅压缩矩阵A中的一个块以填充bufferA并执行macro-kernel。

2. Locating Probing Addresses
-
目标:找到m,n,k;首先需要获得四个循环的迭代次数 ,在根据公式推算出来。(注意P,Q,R,3UNROLL在算法中都是常量,已确定的)
-
Probing address:在itcopy,oncopy,kernel函数的地址(理解:对这些函数的动态调用)
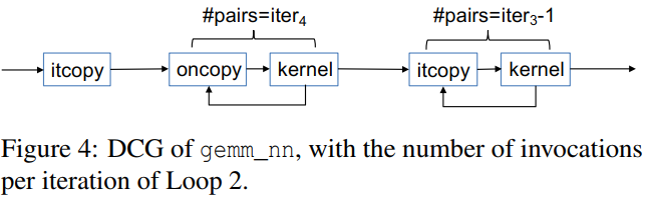
- 在对gemm_nn的一次调用中,整个序列执行了iter1 × iter2次;
- 如何在三个函数(itcopy,oncopy和kernel)中选择probing address,以提高攻击准确性。这三个函数的主体是循环。为了将这些循环与GEMM循环区分开,在本文中将它们称为in-function循环。选择in-function循环内的地址作为probing address有助于提高攻击准确性,因为每次函数调用都会多次访问此类地址,并且可以轻松地将其访问模式与噪声区分开。
3. Procedure to Extract Matrix Dimensions
-
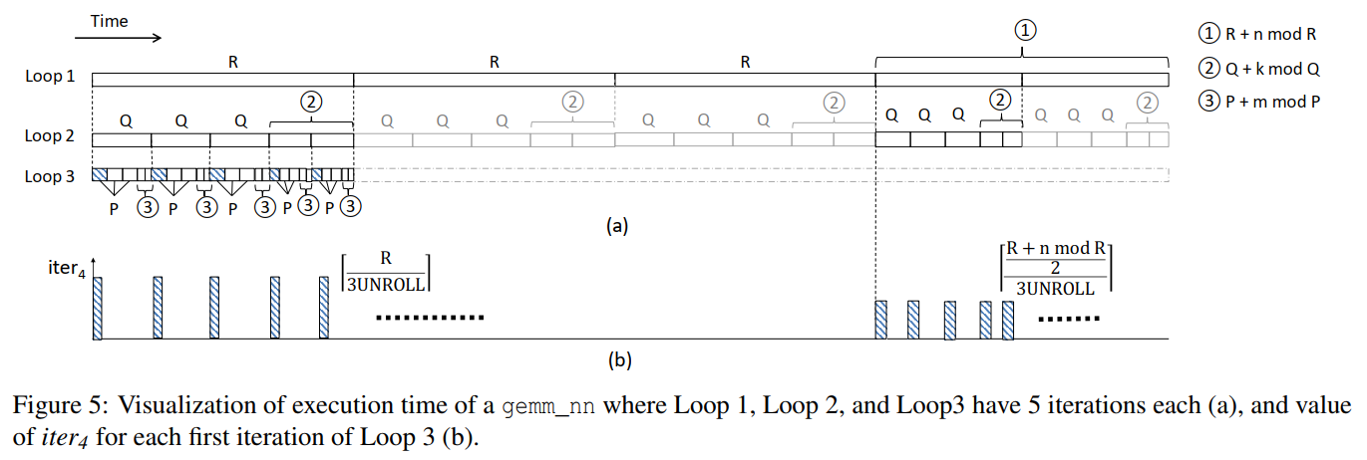
假设Loop 1,2,3均是5次迭代。在Loop 1中,前三次迭代使用R大小的块,后两个迭代每个使用大小为(R + n mod R)/2的块。 在Loop 2中,相应的块大小为Q和(Q + k mod Q)/2。 在Loop 3中,它们是P和(P + m mod P)/2。【OpenBLAS库处理每个循环最后两次迭代的方法 】
-
Loop 1的前三次迭代:
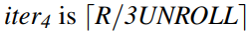
-
Loop 1的后两次迭代:
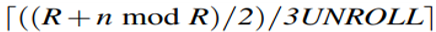
-
提取m,n,k的步骤(一):
-
确定Loop 2迭代的DCG,并提取iter1×iter2。
通过在itcopy,oncopy和kernel的每一个函数中probe一条指令,反复获得了Loop 2迭代的DCG模式。通过计算这些模式的数量,可得到iter1×iter2。
-
-
提取m,n,k的步骤(二):
-
提取iter3并确定m的值。
在Loop 2迭代的DCG模式中,计算itcopy-kernel对的调用次数,这个数加上1即是iter3。
在所有iter3迭代中,除最后两个迭代外,所有其他迭代执行一个大小为P的块; 最后两个执行一个大小为(P + m mod P)/ 2的块。假定迭代的执行时间与它处理的块大小成正比,为Loop 3的“normal”迭代的执行和Loop 3的最后一次迭代的执行计时。
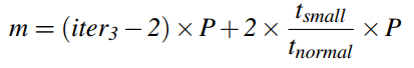
-
-
提取m,n,k的步骤(三):
-
提取iter4和iter2,并确定k的值。
在Loop 2迭代的DCG模式中,计算oncopy-kernel对的数量,可获得iter4。在Loop 2的所有迭代中,除了那些属于Loop 1的最后两次迭代的迭代,iter4的值为
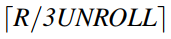 。对于最后两次迭代,iter4为
。对于最后两次迭代,iter4为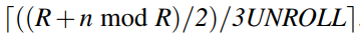 ,它是一个较小的值。因此,通过计数具有较小iter4的DCG模式的数量,并将其除以2,即可获得iter2。
,它是一个较小的值。因此,通过计数具有较小iter4的DCG模式的数量,并将其除以2,即可获得iter2。同第二步类似的计算k,
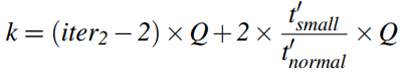
-
-
提取m,n,k的步骤(四):
-
提取iter1并确定n的值。(前面已经得到iter1×iter2和iter2,易得iter1)
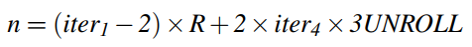
-
Evaluation
1. Experimental Setup
- 攻击平台
- a Dell workstation Precision T1700 with a 4-core Intel Xeon E3 processor and an 8GB DDR3-1600 memory
- L1 cache:32KB icache,32KB dcache;
- L2 cache:256KB
- L3 cache:8MB
- Victim DNN:VGG-16,ResNet-50(都是CNN,ResNet有shortcut连接),在单个线程中执行每个DNN实例
- Attack Implementation:Flush+Reload,Prime+Probe;攻击者和受害者是不同进程且属于不同核,只共享LLC。每2000个时钟周期probe一次在函数itcopy和oncopy的地址。
2. 攻击步骤
- 第一步:cache攻击去监控矩阵乘法和获得矩阵参数
- 第二步:基于DNN超参数和矩阵参数之间的映射对DNN架构逆向工程
- 第三步:修剪剩余的未被发现的超参数的可能值,并为目标DNN架构生成修剪后的搜索空间
3. Attacking GEMM
-
分析结果(Loop 2的一次迭代,监控间隔2000个时钟周期)
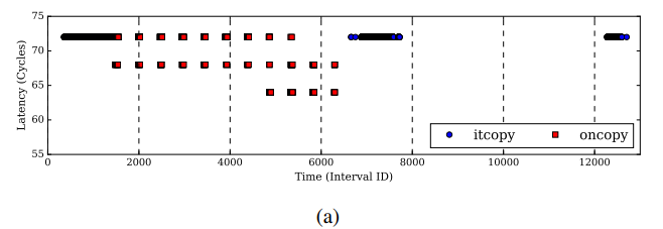
(a)Flush+Reload:它显示了在每个监控时间间隔内,攻击者Reload访问itcopy和oncopy函数中的probing address的等待时间。在图中,仅显示访问时间少于75个周期的实例。这些实例与cache hit相对应,因此与受害者执行相应函数的情况相对应。
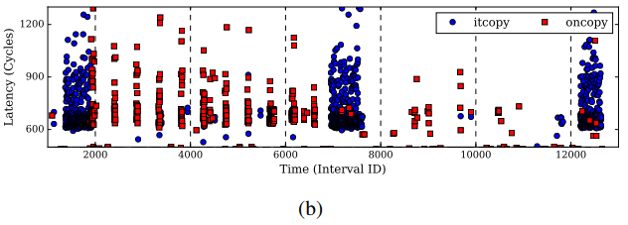
(b)Prime+Probe:它显示了攻击者对conflict address的probe访问的延迟。仅显示访问时间超过500个周期的实例。 这些实例对应于至少一个conflict address的cache miss。 在这种情况下,受害者执行了相应的函数。
-
分析trace: 在这两种trace中,受害者都在时间2,000之前调用itcopy,然后在时间2,000和7,000之间调用oncopy 11次。 然后,它在时间为7,000和13,000之间调用itcopy两次。所以推断是iter4=11,iter3=3。
-
减少噪声
根据所得的结果发现,Prime+Probe的噪声比Flush+Reload的噪声多很多,原因是cache替换策略不确定,需要对victim的cache line所在的cache set全部驱逐保证对victim的cache line的驱逐;
首先,在每个probing函数内部的紧密循环中选择probing address。因此,对于函数的每次调用,都会多次访问相应的probing address,这在Prime + Probe中被视为一组cache miss。计算每个群集中连续的cache miss次数,以获取其大小。噪声的cache miss簇的大小小于受害者访问导致的cache miss簇的大小。于是可丢弃小尺寸的簇。
其次,由于具有三级循环结构,因此每个调用函数(例如oncopy)被重复调用,每次调用之间具有一致的间隔长度。因此,计算相邻群集之间的距离,并丢弃与相邻群集的距离异常的群集。
4. Extracting Hyper-parameters of DNNs
-
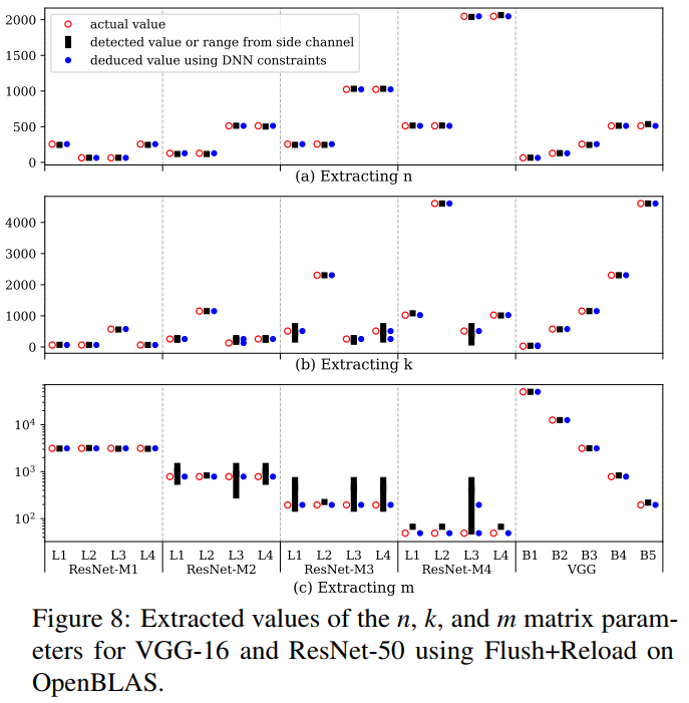
侧信道攻击只能将可能值缩小到一个范围,然后基于这个范围和一些DNN约束推断值,如参数m在ResNet-M2的L1层,实际值是784,检测值的范围是[524,1536],推断值是784。
-
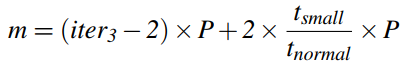
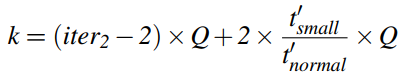
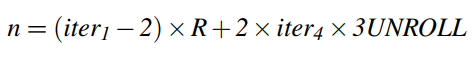
5. Size of Architecture Search Space
-
讨论的超参数的范围:
-
全连接层:
神经元数量:
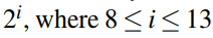
-
卷积层:
filter数量:
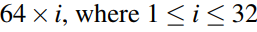
filter大小:整数(1-11之间)
-
- Size of the Original Search Space
- VGG-16:
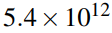
- ResNet-50:
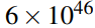
- VGG-16:
-
Determining the Reduced Search Space
-
首先通过定位shortcut确定层间的可能连接;对每个可能的连接,计算每一层可能的超参数。最后搜索空间计算为:
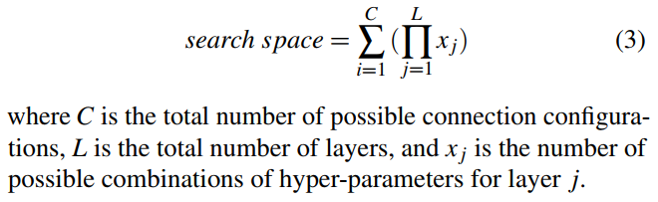
-
确定层间的连接:以ResNet-M1为例,首先根据Sec 4.3的方法,利用inter-GEMM的时延来决定shortcut和sink 层的存在。
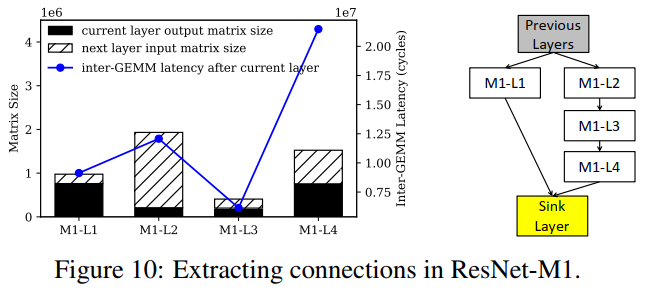
在考虑了它的输出矩阵大小和下一层的输入矩阵大小,图中在M1-L4之后的inter-GEMM时延比预期的长,说明M1-L4之后的层是一个sink层。(如果没有shortcut,GEMM间的延迟就与上一层输出大小和下一层输入大小之和成线性关系。)
接着,检查previous layes的输出矩阵维度来定位shortcut的source。(shortcut的source层必须具有与非顺序连接的其他source层相同的输出维度,即shortcut只连接具有相同矩阵维度的层)考虑n,m(Fig 8),M1-L1是source,M1-L1和M1-L2不是顺序连接的(显然地,M1-L1的输出矩阵和M1-L2的输入矩阵的大小不相同)。
-
确定每一层的超参数:(Table 3)以ResNet-M2为例
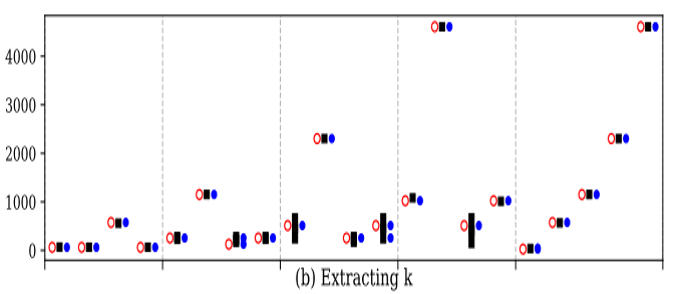
首先,提取filter的数量。Fig 8的n(M2-L3)= (the number of rows in F’) 使其靠近64的乘积,令其为512。
接着,用公式确定filter的宽度和高度。考虑L2和L3是顺序连接的,k(M2-L3)= (the number of rows in in’ of current layer)为[68,384],n(M2-L2)= (the number of rows in out’ of the previous layer)为118。因为要确保k(M2-L3)/ n(M2-L2)的平方根是整数,所以只能推测k(M2-L3)为118。
-
确定Pooling和striding:使用连续层之间的m维(即输出通道大小)之差来确定池或步幅大小。
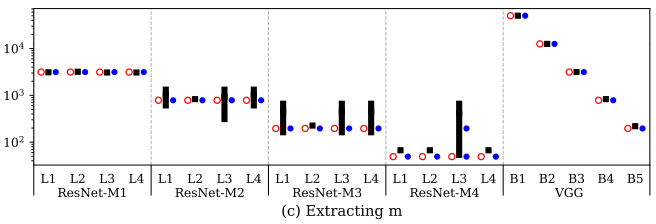
ResNet-M1的最后一层和ResNet-M2的第一层的m维是不同的,表明存在一个pool layer或一个stride操作。
举例:m(M1-L4)=(the number of columns in out’ for the current layer)为3072,m(M2-L1)=(the number of columns in in’ for the next layer)为[524,1536],要确保m(M1-L4)/ m(M2-L1)是一个整数,则 m(M2-L1)一定得是768,pool或stride的宽度和高度必须为2。
-
-
Size of the Reduced Search Space

Discussion
1. Countermeasures
- 修改BLAS库,所有的BLAS库都为了性能用优化的分块矩阵乘法。但这样做会导致较差的cache性能。
- 减少矩阵的维度。在OpenBLAS和MKL中,如果矩阵大小小于或等于块大小,将无法精确推断出矩阵大小。此缓解措施通常对卷积网络中的最后几层有效,卷积网络通常使用较小的filter大小。但是,它不能保护矩阵较大的层,例如使用大量filter和输入激活函数的层。
- cache分区,如Intel CAT技术;或者一些cache安全机制,如PLCache,SHARP,CEASER等。但还没有在实际生产中应用这些机制。
2. Related Work
- [29]设计了第一种攻击来窃取在硬件加速器上运行的CNN架构。 他们的攻击基于不同的威胁模型,这要求攻击者能够监视受害者访问的所有内存地址。 本文的攻击不需要这种提升的特权。
- [27]提出使用基于缓存的侧信道攻击对DNN架构的粗粒度信息进行逆向工程。 他们的攻击没有Cache Telepathy强大。 他们只能获取层的数量和类型,但无法获取更详细的超参数,例如完全连接层中的神经元数量和卷积层中的过滤器大小。
- [9]提出使用电磁侧信道攻击对嵌入式系统中的DNN进行逆向工程。