组会-20191129-组会纪要
主题:Robust Website Fingerprinting Through the Cache Occupancy Channel
Background
概念背景知识:
-
浏览器指纹识别(Browser Fingerprinting):通过Web浏览器收集信息包括从硬件到操作系统再到浏览器及其配置等信息,以构建设备指纹并且识别用户设备的过程。重点在于识别用户的机器设备。
-
网站指纹识别(Website Fingerprinting):通过观测用户计算机状态,识别出用户的网络行为,判断出用户访问的是哪个网站,更偏向于用户个人信息层面。
浏览器指纹识别和网站指纹识别是两个不同的研究领域,但是未来可能会结合利用。
-
Tor匿名网络:洋葱路由,将流量包裹在加密层中(像洋葱那样),从而尽可能好地在将数据内容在发送方和接收方之间匿名保护起来。
技术背景知识:
-
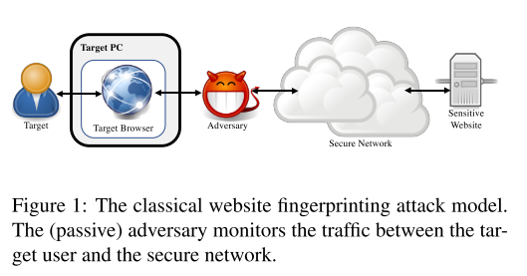
基于网络流量的攻击
在传统攻击模型中,攻击者对用户的通信流量进行统计分析,即使在加密情况下,也可以通过数据包的大小、数据包时序、通信方向等特征来进行概率推断,并且研究分类方法来进行更好的网站预测。
-
基于Cache 侧信道的攻击
Prime+Probe技术
-
Prime: 攻击者用预先准备的数据填充特定多个cache 组
-
Trigger: 等待目标响应服务请求,执行程序,将cache数据更新
-
Probe: 重新读取Prime 阶段填充的数据,测量并记录各个cache 组读取时间
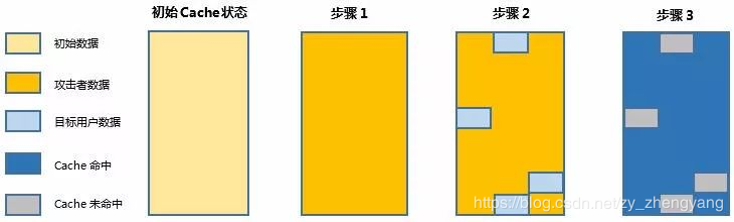
cache命中和失效对应响应时间有差别,攻击者可以通过访问时间的差异,推测cache信息。
-
-
基于网络流量攻击的防御
主要思想是注入随机延迟和虚假掩护流量,以扰乱流量特征。 这些防御措施的一个共同点是需要在延迟/带宽和隐私之间权衡,因此它们面临着一些实地部署上的障碍。
-
基于Cache侧信道攻击的防御
为了区分缓存命中和未命中,缓存攻击通常需要高分辨率计时器。因此浏览器开始降低它们提供的计时器的分辨率,以应对缓存侧通道攻击。力度最大的是Tor浏览器,将计时器分辨率限制为100 ms或10 Hz。
本文贡献:
-
设计并实现了一种基于Cache占用的侧信道攻击,可以在低计时器分辨率下运行。
-
根据浏览器加载时的缓存活动信息,使用CNN和LSTM对网站进行指纹识别。
-
证明了基于缓存占用的指纹识别在密闭和开放模型下都具有很高的准确性。
-
证明了基于缓存的指纹既包含网络活动信息,也包含设备渲染活动的信息。 因此,即使在存在延迟或者虚假流量的情况下,也可以保持较高的准确性。
-
设计并评估了一种在缓存中引入噪声的反制手段,完全阻止了对Tor浏览器的攻击,并且性能开销在可接受范围内。
Overview
本文威胁模型:
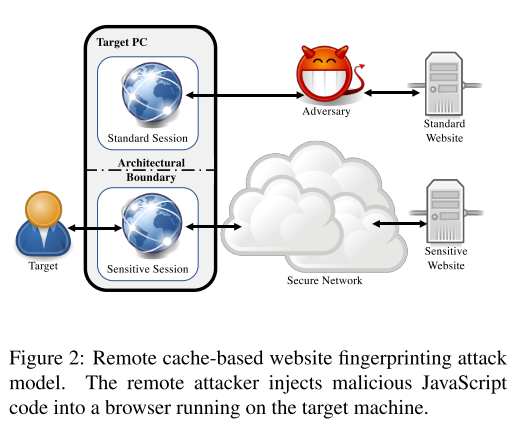
- 在这个模型中,用户会有两个并发浏览器会话,一个会话是Standard Session(被攻击者控制),包含了恶意JS代码;另一个是用户自己的敏感会话。
- 这两个会话可以在一个浏览器上,也可以在不同的浏览器中,或者在虚拟机中的浏览器中,只要他们共享基础的硬件。
- 攻击者可以用钓鱼、广告等手段诱使用户访问自己的网站,从而执行恶意代码,来获取用户敏感会话的信息。
Data Collection
memorygram
- 在传统的基于cache侧信道攻击中,用户数据主要用memorygram来表示, memorygram中包含了在给定时间段内以恒定采样率测量的缓存访问延迟信息。
- 本文的memorygram中包含的是在给定时间段内的Cache 占用率信息,在浏览器加载和显示网站时收集memorygram,并将数据用作网站分类的指纹。
Cache 占用率
Prime + Probe技术测量单个cache set访问时间,而本文的攻击测量整个cache中的占用量。
- JavaScript攻击会分配LLC大小的缓冲区,并测量访问整个缓冲区的时间。
- 用户对内存的访问将我们缓存中的内容从缓存中逐出。
- 重新访问整个缓冲区,测量当前的访问时间。
- 访问缓冲区的时间与用户使用的cache Line的数量大致成比例
缺乏地址信息
与Prime + Probe技术相比,基于cache占用的攻击无法得到用户访问的具体地址信息(因为没有对特定cache set进行比较分析),但是作者提出现代浏览器具有复杂的内存分配模式,每次下载页面内存分配会更改,并且地址信息并不会带来指纹特征。
针对Tor的memorygrams
Tor的计时器分辨率限制为100ms,本文不测量对cache扫描需要多长时间,而是计算在100ms的间隙内整个cache可以扫描几次。 另外,由于Tor网络响应时间较慢,适度延长单位时间段。
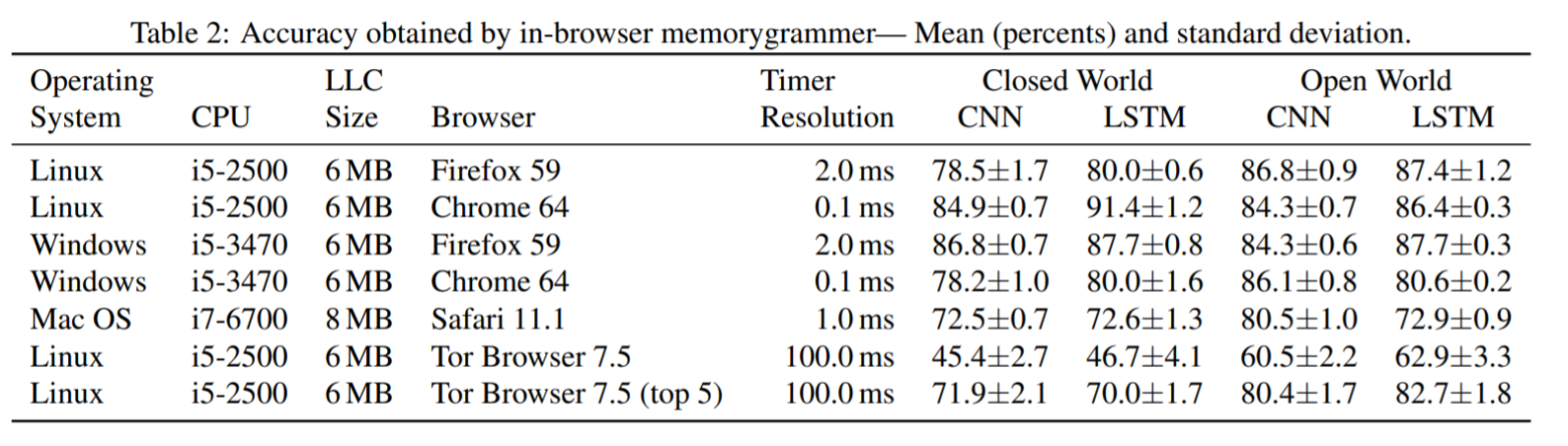
Closed World Datasets
封闭环境下的假设在于,攻击者认为用户访问的网站只在一个相对较小的网站列表中,攻击者可以为每个网站准备和训练分类器。
因此本文中的Closed World Datasets采用Alexa前100的网站,包含100条网站上的100条痕迹,总计10,000个memorygrams 。
Open World Datasets
在这种情况下,攻击者希望在监视敏感网站的访问并对其高精度分类之外,将大量不敏感的网页,全部标记为“不敏感”。因此本文的Open World Datasets在closed world datasets基础上增加了5,000个memorygram,这每一个memorygram都是由单独的网站收集的。
Demo示例
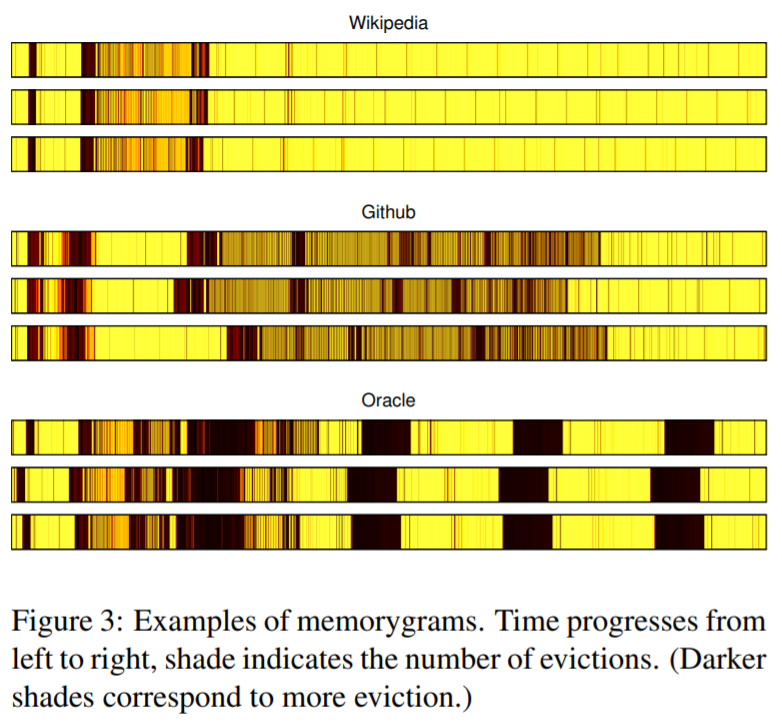
每个memorygram以彩色条显示,时间从左到右。
阴影对应于每次的cache活动。(浅色阴影表示逐出的次数较少)
我们看到每个站点的三个memorygram虽然不相同,但是彼此相似。 但是,不同网站的memorygram彼此非常不同。 这表明memorygram可用于识别网站。
机器学习
问题构建: (1)攻击者多次访问每个目标网站并收集一组标记的跟踪信息(memorygram),每个memorygram都对应于 对这个网站的访问。 (2)使用经典的机器学习方法在这些标记上训练分类器算法或深度学习方法。 (3)当用户访问网站时,应用分类器,对memorygram进行分类并输出结果。
Deep Learning Models:
- CNN、LSTM分类器
Results
Robust Test
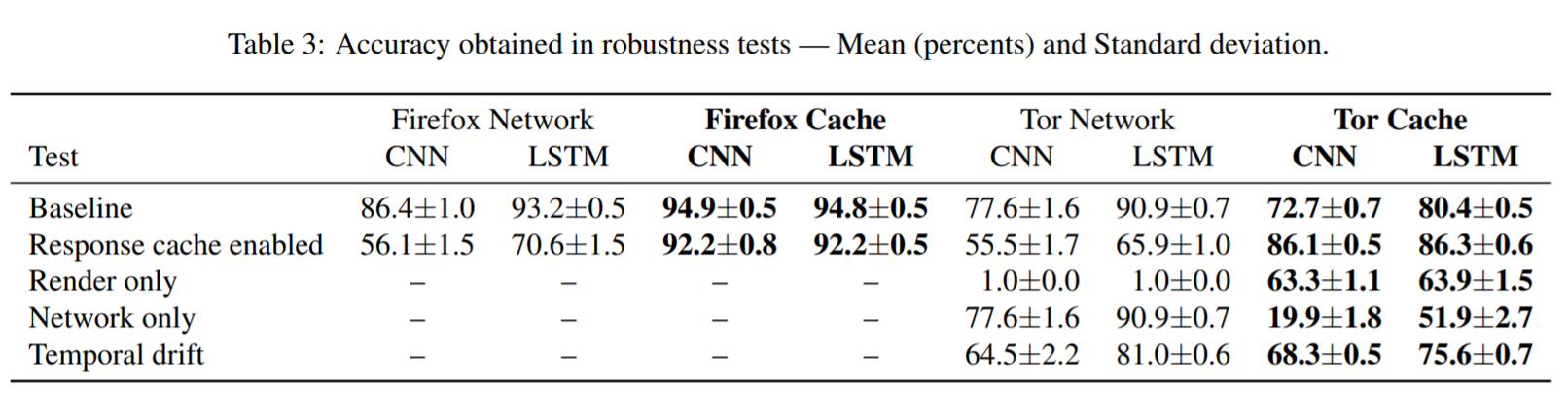
- 文章中提到,基于native code的memorygrammer比 in-browser JS code在准确度上要高,猜测原因是本机代码memogrammers提供了更高的探测精度。(是否可用WebAssembly)
反制措施
-
Cache Activity Masking
分配一个cache大小的缓冲区,并在一个循环中依次访问缓冲区中的每个cache Line,从而将整个cache的内容evict出去。 可以作为浏览器插件在浏览器中应用这种屏蔽技术。
实验表明,这种反制措施在Firefox上取得了一定的效果:在封闭世界中,攻击成功率由79%下降到73%;在开放世界中,攻击成功率由86%下降到77%。
另外SPEC CPU benchmark显示速度降低约5%(整个几何平均值基准),最坏情况下的速度会降低14%。 作者对CPU基准性能的影响是可以接受的。
-
缓存随机化
-
缓存分区
-
CACHEBAR
问题与讨论
- 基于cache的网站指纹识别需要进行定制,以使其适应不同用户的不同计算机硬件配置,特别是最后一级缓存的设置,使用太大或太小的缓冲区会减少技术的有效性。但是,作者提出目前四种缓存配置(4096 or 8192 sets, 12 or 16 ways)已经覆盖了大多数Intel核心处理器。
-
如果用户硬件配置是事先已知的(例如某个特定用户被选出进行攻击),攻击者可以自定义JavaScript攻击代码以匹配目标PC的参数。
- 可以使用JavaScript远程确定未知目标的缓存配置。
- Cache其实始终处于一定程度的活动状态,跟踪什么时候开始是一个问题。本文是隐式地根据下载的开始时间来确定跟踪的开始时间。 但是由于网络条件的变化,在跟踪开始和渲染开始之间最多会达到6s。
- 噪声问题以及与其他应用的兼容性问题。