组会-20191108-组会纪要
主题:2019-RAID-Time and Order_Towards Automatically Identifying Side-Channel Vulnerabilities in Enclave Binaries 论文讨论
Background
- 研究动机:
- SGX设计目标是保护需要高安全级别的应用程序的机密性,侧信道成为其主要的安全威胁
- 因为SGX的威胁模型中,认为攻击者拥有操作系统级别的特权,攻击面增大
- 目前已经发现大量侧信道攻击,如分支预测单元、CPU cache和分页结构等
- 基本思路:
- 侧信道漏洞的根本成因是enclave代码本身存在secret-dependent的控制流
- 直观的想法是找到一个秘密值的大集合(如enclave程序的输入),用这些秘密值来运行程序,收集程序关于由不同的输入产生的控制流转移的执行路径,对其进行分析
- 挑战:
- 怎么生成有效的秘密值使得在不同粒度上(page, cache, branch)获得执行路径(输入生成)
- 怎么收集执行路径,尤其是跟路径相关的时序信息;其中静态分析不能收集到准确的时间信息,动态分析需要解决覆盖度的问题(路径构造)
- 怎么表示执行路径,当有多个执行路径时怎么执行交叉比较(路径构造和漏洞识别)
- 怎么根据检测到的漏洞定量地分析信息泄露(结果分析)
- 怎么生成有语义的、攻击者感兴趣的输入(方法优化)
- 本文贡献:
- 提出了一种检测enclave二进制文件中基于时序和基于顺序的控制流侧信道漏洞的方法ANABLEPS
- 实现了模糊测试、符号执行和硬件支持的执行路径跟踪的集成
- 对现实世界中的enclave二进制文件的敏感控制流漏洞的大规模分析
Overview
- 定义:
- 本文中的秘密值是:enclave程序的输入
-
对于一个enclave程序,如果不同的输入导致程序的执行单元执行顺序不同或访问时间不同,即产生在顺序或时序上不同的执行路径,则认为其存在侧信道漏洞。反之,如果程序在面对不同的输入时的执行路径是唯一的,则认为其没有侧信道漏洞。
- 如果输入集的元素个数与获取到的不同的执行路径个数相同,即一一对应,则认为该输入集是完全泄露的
- 由于难以获得全部的输入空间,文中用到的输入集是输入空间的子集,检测到的漏洞仅在固定enclave和固定输入集下有意义
- 本文考虑了两类输入: I(syntactic),从程序分析中自动生成的输入集; I(semantic),由开发人员提供的具有语义的输入集
- 威胁模型与假设:
- 已知enclave程序的代码,尤其是代码布局和映射
- Enclave程序没有使用ASLR
- 攻击者能够运行、重置和终止目标enclave,能够控制整个操作系统
- 考虑利用branch、cache、page访问行为和时间信息的侧信道,不考虑硬件架构造成的侧信道
- 考虑代码访问相关(控制流)的侧信道,不考虑数据访问模式(数据流)导致的侧信道漏洞
Design
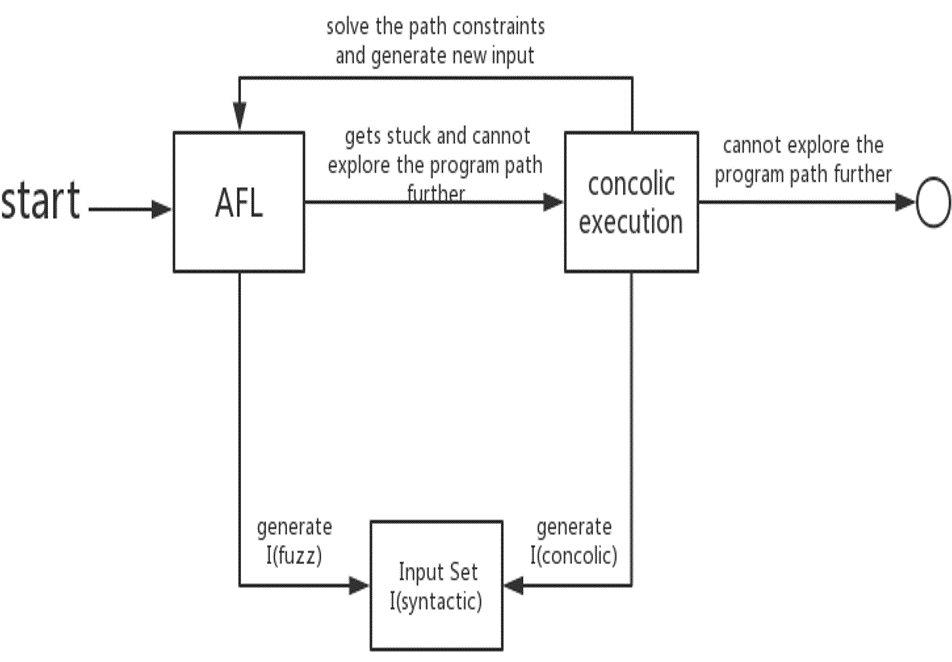
- Input Generation(输入生成)
- Driller: fuzzing(AFL)+ concolic execution(动态符号执行,angr)
- Input set:I(syntactic) = I(fuzz) U I(concolic)
- Trace Construction(路径构造)
(1)路径收集
- Intel Processor Trace (PT)
- Intel PT收集程序的控制流转移的信息,并且会连同时间戳一起记录
- 但是记录的时间不够细粒度,基本块的执行时间只能近似
- ANABLEPS设置足够大的内存缓冲区,使得没有任何数据包会在动态分析中丢失,被记录的数据包会被解析并记录在日志文件中,这些都会用于ED-CFG的构造
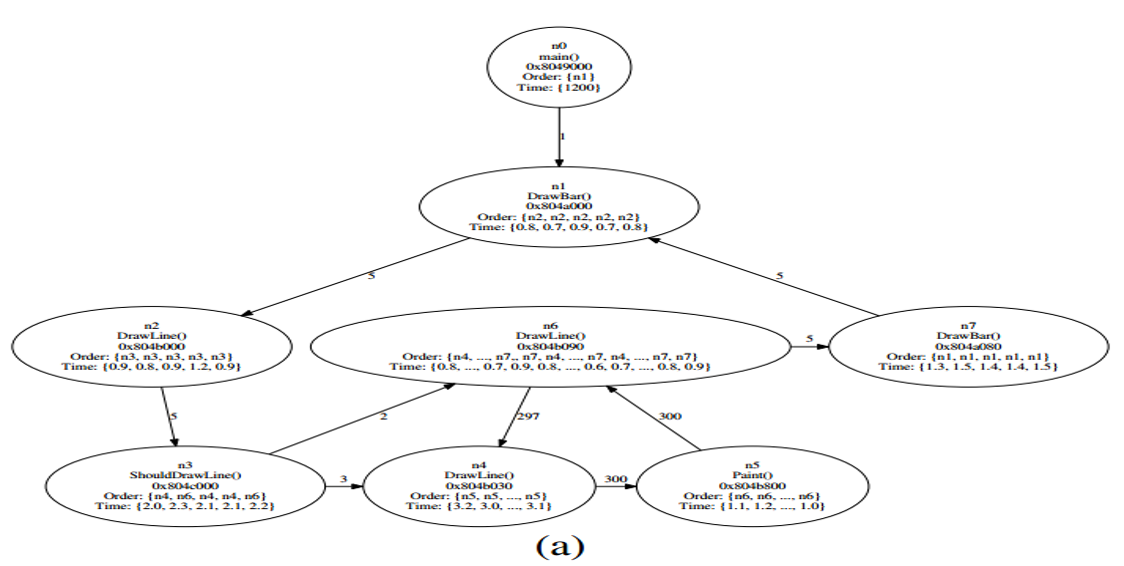
(2)ED-CFG构建
- 首先根据PT的trace file构造D-CFG,每个节点表示一个基本块,边表示基本块间的控制流转移,边的权重是该转移的执行次数
- 然后添加执行顺序和时间使其变成ED-CFG,其中每个基本块当中维护两个list来记录执行顺序和时间。另外:Order列表包含跳转到的下一个节点,Time列表包含该节点每次执行的时间
- 时间的近似是指得到的lower bound和upper bound Upper bound:记录在CYC (Cycle Count)数据包中的CPU时钟周期 Lower bound:这个基本块中的所有指令的时延总和
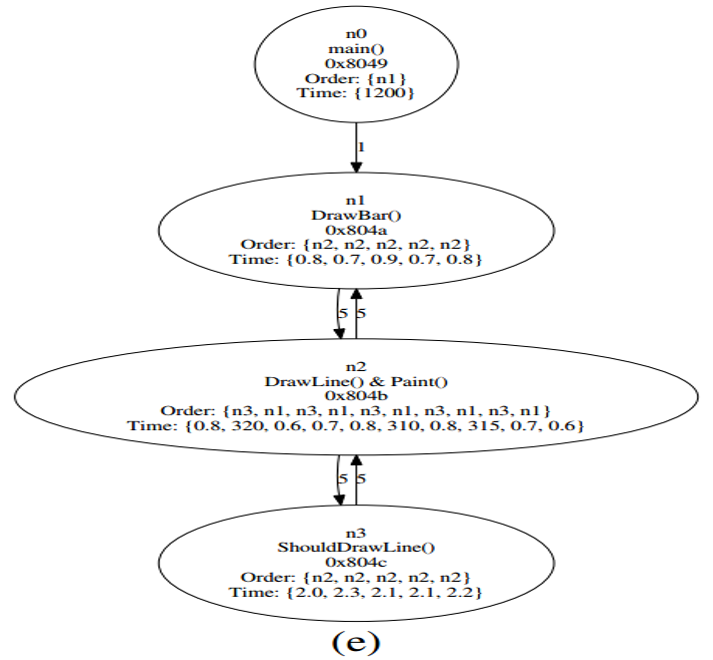
(3)生成page级别和cache级别的控制流图
- 根据基本块的地址将处于同一页面的节点合并,将跨越两个页面的节点拆分;
- 删除同一页面的节点间的边,对页间存在控制流转移的增加边并更新权重;
- 根据合并后的节点更新顺序列表,时间列表则按照执行顺序累加属于同一页面的时间信息。
(4)流程如图:

- Vulnerability Identification(漏洞识别)
(1)基于顺序的漏洞识别 对于不同输入,两个控制流图相等当且仅当node和edge的集合完全相同,包括每个node的Order list和edges当中的执行次数。 (2)基于时间的漏洞识别 Order没有问题时,检查Time list,控制流图1中的第l个节点的Time list中的第k个元素与控制流图2中的第l个节点的Time list中的第k个元素相比较;每个节点的时间列表的元素是一个二维数组,两个值为使用相同的输入执行10次得到的时间平均值和标准差
Evaluation
- 实验设置
- 输入生成:Driller(AFL and concolic excution)
- 收集运行时信息:perf去配置Intel PT
- PT数据包解析器:基于libipt
- ED-CFG构建和交叉比较:python脚本分析PT数据包
- 与二进制代码匹配解析后的地址:pyelftools library
- 消除输入的约束并计算输入空间:扩展angr
- 实验样本
-
用library OS运行传统的应用程序(Grephane-SGX)当做是SGX程序
-
8个程序:data analytics, machine learning, image processing, text processing
- 实验结果
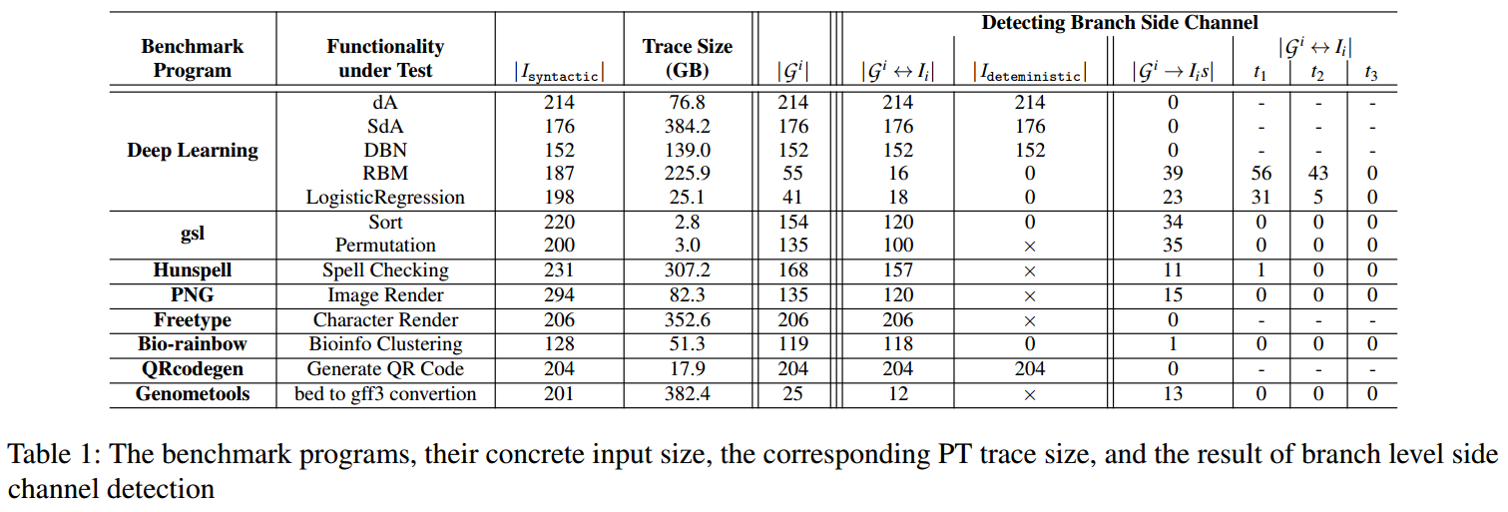
(备注:第6列:基于顺序的侧信道,一对一映射;第8列:基于时序的侧信道,一对多映射;第9-11列:不同阈值下基于时序的侧信道,一对一映射,这个不同阈值指的在没有order-based的一对一映射下,时间差在阈值范围内的)
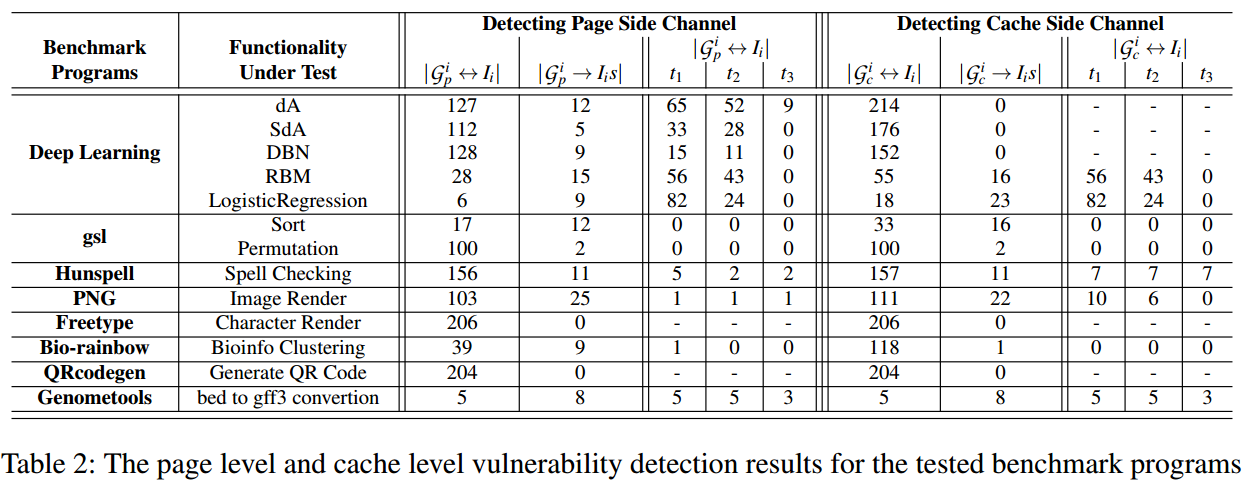
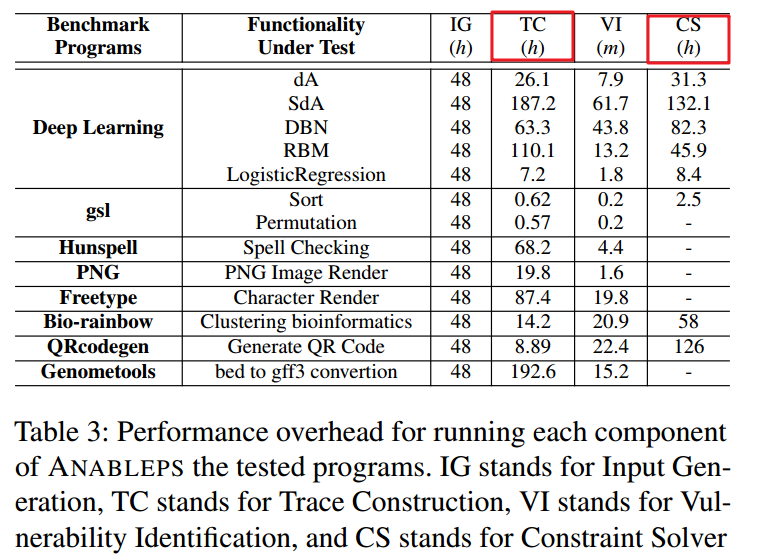
- 结果总结
- ANBLEPS性能瓶颈主要在路径构建和约束求解,受到trace file大小和计算能力的影响
- 相对于branch-level漏洞,更少一对一的映射在page-level和cache-level上被检测到
- 相比于page level和cache level,在branch level上基于时间信息来区分输入是相对困难的
- 不同的应用程序能够根据控制流图和顺序时间等信息区分输入的能力是不同的,如QRcodegen和Deep learning在branch level上能够较好地根据execution traces区分输入;在gsl中的函数Sort会有多个输入对应相同的execution trace
Exploitability
- 开发人员辅助的漏洞分析
与之前在第4部分中的自动化分析步骤唯一的区别是输入生成的步骤和漏洞识别中的决定G的输入空间的步骤被跳过了,因为感兴趣的输入集现在是由开发人员提供的。
- 例子

文中提出编译后,将dA_get_corrupted_input()中的for循环编译为两个cacheline,分别表示为m1和m2,将函数binomial()编译为两个连续的cacheline。 将其第一个缓存行表示为m3。因此,如果数组x的第i个元素是0,则执行的cacheline的顺序是[m1,m2]。否则,执行的顺序变成[m1,m2,m3,m2]。
Limitations
局限性:
- 对secret-dependent数据访问暂时不在考虑范围,ANABLEPS没有考虑依赖于秘密值的内存指针或数组索引
- 尽管ANABLEPS已经涵盖fuzzing和concolic execution等工具,但是还不能完全生成完整的输入集
- constraint solver的能力有限,给定一个程序的输入,ANABLEPS依赖于符号执行来收集约束,这些约束都由constraint solver来解决,但并不是所有约束都能被解决,且可能会花费大量的时间去解决这个约束
讨论
- 文中的实验对象较少,仅为8个在Grephane-SGX运行的程序,其中没有涉及侧信道攻击中最常见的攻击对象密码算法;对于这一问题,(1)应该是考虑到密码算法的输入较为庞大,不利于生成输入集;(2)密码算法中的分组或者赋值等操作属于数据流层面,文中的方法仅针对控制流,目前是无法分析完全的。
- 文中方法对于寻找漏洞是可行的,但是对于漏洞利用的讨论没有深入;即解决了漏洞在哪里的问题,但没有解决漏洞如何利用的问题。
- 文中将enclave程序中的输入定义为秘密值,但是观察实验程序样本发现,这些输入并不全是有价值的秘密值,如sort排序程序之类的输入并不是我们特别关心的;对于输入集的生成或秘密值的定义仍然是需要优化的问题。
- 文中对存在侧信道漏洞的定义限制是否过强,即方法获取到的侧信道漏洞的精度是否足够。