组会-20191102-讨论纪要
讨论主题
uXOM: Efficient eXecute-Only Memory on ARM Cortex-M ( posted on USENIX 2019 )
Donghyun Kwon1,2; Jangseop Shin1,2; Giyeol Kim1,2;
Byoungyoung Lee1,3; Yeongpil Cho4; Yunheung Paek1,2
1: ECE, Seoul National University
2: ISRC, Seoul National University
3: Computer Science, Purdue University
4: School of Software, Soongsil University
概述
代码通常包含对安全敏感的信息,例如知识产权(核心算法),敏感数据(加密密钥)以及可用于发起代码重用攻击(CRA)的gadgets,因此代码泄露攻击(code disclosure attacks)是对计算机系统的主要威胁之一。为了阻止此类攻击,安全研究人员设计了一种强大的内存保护机制——eXecute-OnlyMemory(XOM),该机制定义了允许执行指令但禁止对数据进行读写的特殊内存区域。由于XOM的潜在价值,目前许多最新的高端处理器都在其硬件中增加了对XOM的支持(x86: EPT/MPK; aarch64: MMU),但低端嵌入式处理器尚未为XOM提供硬件支持。
本文提出了一种新技术——uXOM,它以一种安全且经过高度优化的方式在Cortex-M系列处理器上实现了XOM。uXOM通过利用Cortex-M中的特殊架构特性(非特权的内存存取指令和MPU)来实现其安全性和效率。实验表明,与纯软件实现的XOM(基于SFI)相比,uXOM在执行时间,代码大小和能耗方面都具有更高的效率。
背景知识
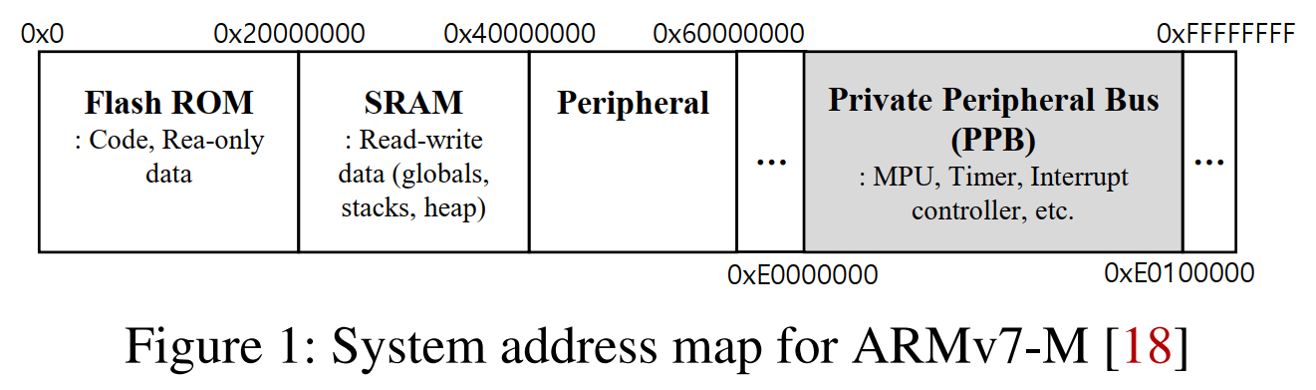
PPB内存区域
ARMv7-M架构不支持内存虚拟化,并且代码,数据和其他资源固定在特定的地址范围内,上图展示了其内存空间的布局。其中,从0xE0000000到0xE00FFFFF的1 MB区域是PPB区域,该区域映射了各种用于控制系统和监视系统状态的寄存器,例如定时器,中断控制器和MPU。PPB与其他内存区域的不同之处在于,它仅允许部分内存指令在特权模式下对该区域进行读写。通常,通过改写PPB区域内MPU的配置文件,可以配置各个区域的访问权限,但PPB的访问权限是固定的,MPU也无法覆盖其默认配置(特权模式下可读可写RW,非特权模式下无任何权限NA)。
MPU
MPU为Cortex-M处理器提供了内存访问控制功能。它具有以下特点:
- 支持5种访问权限:RWX, RW, RX, RO, NA
- 可配置有限数量(通常为8或16)的可重叠内存区域
非特权内存指令
非特权内存指令是ARMv7-M指令集中提供的特殊类型的内存访问指令。这些指令的主要特点在于,无论当前的执行权限如何,它们始终以无特权的方式执行存储器访问。因此,使用这些指令进行内存访问时,受到MPU针对非特权模式下的访问控制的约束。非特权内存指令仅支持32位编码,仅支持立即数偏移寻址模式,不支持独占式的内存访问(多核内存一致性)。通常,这些指令带有常见的后缀“ T”(例如,LDRT/STRT)。
异常处理
在ARMv7-M架构中,向量表偏移寄存器(VTOR)指向的向量表中指定了每个异常对应的异常处理程序的位置,具有以下特点:
- 通过硬件机制自动在堆栈上保存和恢复CPU上下文(包括程序状态寄存器xPSR,返回地址lr,r12,r3,r2,r1和r0)
- 提供了两种类型的sp
- main sp: 仅可在异常处理程序内部使用
- process sp: 用于其他场景
- sp具体指向哪种类型的sp由系统控制寄存器决定
威胁模型与假设
Threat Model
- 攻击者只能在运行时对软件进行攻击,以达到以下能力:
- 执行任意内存读写
- 劫持控制流
- 不考虑对固件的离线攻击
- 不考虑硬件攻击(例如,总线探测,内存破坏等)
Assumption
- 固件的所有软件组件均不受信任,包括异常处理程序
- 所有软件组件均在特权模式下执行
设计与实现
Basic Design
uXOM旨在为基于Cortex-M处理器的商用裸机嵌入式系统提供XO内存权限,从而可以有效地防止代码泄露攻击。uXOM试图通过利用硬件特性(非特权内存指令和Cortex-M处理器提供的MPU)来最大程度地降低性能开销。基本方法如下:
- 将所有内存指令转换为非特权内存指令;
- 配置代码区域特权模式下权限为RX,非特权模式下权限为NA。
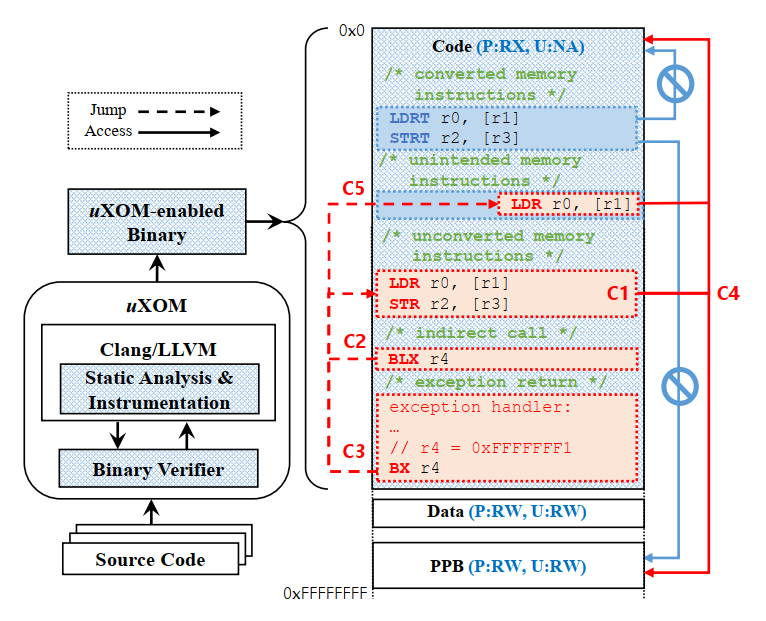
Challenge
如上所述,uXOM的基本原理非常简单直观。但是,要实现uXOM,必须克服一些挑战,以构建一个适用于实际程序且不能以任何方式绕过的系统。实现uXOM的有如下挑战:
- C1.Unconvertible memory instructions:不是所有的内存指令都可以转换为非特权内存指令,原因如下:
- 非特权内存指令不支持用于实现锁机制的独占内存访问指令
- 非特权内存指令无法访问PPB区域,配置MPU
- C2.Malicious indirect branches:攻击者可通过劫持控制流跳转到未转换的内存指令,从而利用这些指令篡改MPU配置;
- C3.Malicious exception returns:异常处理过程中,攻击者可通过破坏栈上的CPU上下文劫持控制流,跳转到未转换的内存指令,从而利用这些指令篡改MPU配置;
- C4.Malicious data manipulation:攻击者可通过构造MPU配置函数参数,篡改MPU配置;
- C5.Unintended instructions:Cortex-M处理器支持Thumb-2指令集,它支持16位和32位宽度的指令混合编码。因此,攻击者可以通过跳到32位指令的中间来执行意料之外的指令,也可以通过嵌入在代码中的立即值执行指令。而这些指令有可能存在可访问PPB区域的内存指令,攻击者可利用这种指令篡改MPU配置。
Implementation
uXOM是基于LLVM框架(LLVM 5.0)中的编译器pass和二进制分析程序(Radare2)实现的。在编译期间,uXOM执行静态分析和代码检查,以生成启用uXOM的二进制文件(即固件),将二进制文件刷到开发板上并启动系统后,uXOM会自动对正在运行的代码强制执行XO权限。
Instruction Conversion
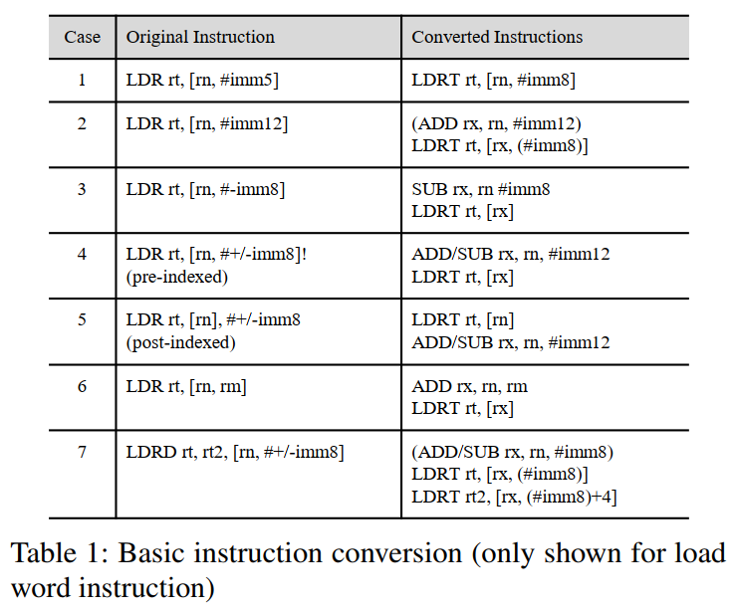 上图总结了本文应用于部分内存指令的转换过程。Case 3-6需要额外的ADD或SUB指令来计算存储器地址。如果在其他指令中再次使用了rn寄存器,则可能需要额外的寄存器来存储计算出的地址。由于时在寄存器分配阶段之前执行转换,因此不必担心物理寄存器,可让编译器为临时结果选择最佳寄存器。LDM/STM指令未在表中显示,因为它们仅在寄存器分配后的优化过程中出现。因此,当优化过程尝试创建LDM/STM指令时,可直接禁用优化以防止生成这些指令。
上图总结了本文应用于部分内存指令的转换过程。Case 3-6需要额外的ADD或SUB指令来计算存储器地址。如果在其他指令中再次使用了rn寄存器,则可能需要额外的寄存器来存储计算出的地址。由于时在寄存器分配阶段之前执行转换,因此不必担心物理寄存器,可让编译器为临时结果选择最佳寄存器。LDM/STM指令未在表中显示,因为它们仅在寄存器分配后的优化过程中出现。因此,当优化过程尝试创建LDM/STM指令时,可直接禁用优化以防止生成这些指令。
Permission Control
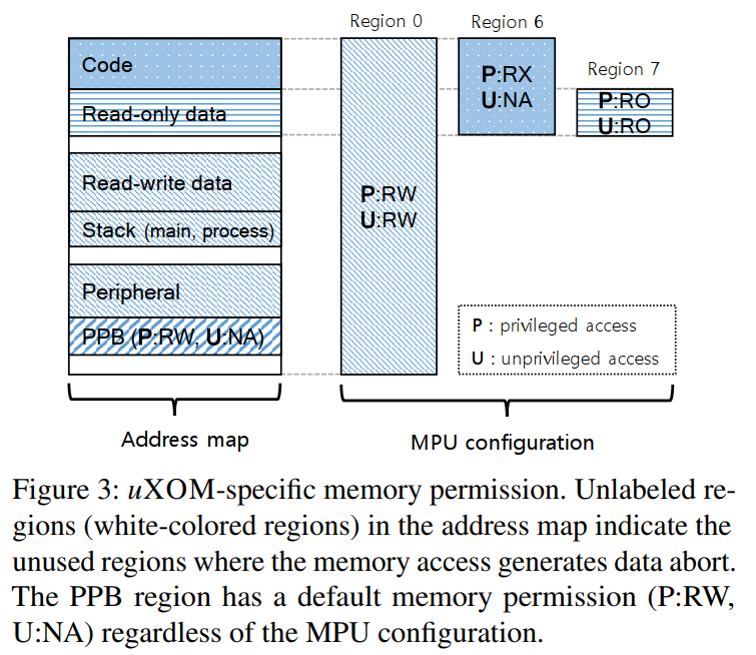 上图显示了uXOM的默认MPU配置。当内存区域配置有重叠时,仅区域ID较大的权限配置有效。这些配置在重置处理程序(reset handler)的早期阶段完成,将在处理器重置时被调用。因此,uXOM的权限配置会在系统启动的早期阶段被激活,然后攻击者才有可能控制系统。
上图显示了uXOM的默认MPU配置。当内存区域配置有重叠时,仅区域ID较大的权限配置有效。这些配置在重置处理程序(reset handler)的早期阶段完成,将在处理器重置时被调用。因此,uXOM的权限配置会在系统启动的早期阶段被激活,然后攻击者才有可能控制系统。
Solving Challenges
Finding Unconvertible Memory Instructions ➔ C1
不对下列指令进行转换,这些指令的安全性由其他技术保证。
- 通过指令编码的opcode找到独占内存指令
- 通过检查内存访问目的地址找到访问PPB区域的内存指令
Atomic Verification Technique ➔ C4
- 在执行未转换的指令前添加验证过程

- 在指令执行期间关中断以实现原子性,防止攻击者在验证过程执行之后通过产生异常,篡改数据

Atomic Verification Technique ➔ C2,C3
- 使用专用的寄存器作为未转换指令的存储器地址寄存器
- 强制该寄存器遵循以下两个不变属性:
- IP1)执行原子验证过程时,专用寄存器保存目的地址
- IP2)未执行原子验证验证时,专用寄存器存储其他无关量
如果使用通用寄存器来作为专用寄存器会导致系统性能降低,因此可选用异常处理过程中的main sp作为专用处理器。为了保证以上两个不变属性,需要在下图所示位置检查sp的值。

Handling Unintended Instructions ➔ C5
- 使用静态二进制分析程序找出所有可利用的指令
- 将安全指令替换为可利用指令

Optimizations
根据实验结果,非特权内存指令所消耗的CPU始终周期与普通的内存指令相同,但是,非特权指令的大小为32位,而许多普通指令的格式为16位。而且,转换指令的时候可能需要额外的指令,这样也会增加代码大小和性能开销。由于嵌入式内存有限,因此代码大小也是嵌入式应用程序中的一个关键因素。因此,如果可以确保不损害uXOM的安全性,那么将内存指令保留为原始形式将是有益的。实际上,由于某些内存指令它们本质上是安全的,或者可以通过一些额外的方法保证它们的安全性,因此不需要转换该类指令。主要包括以下两类:
- pc-relative指令
- 目的地址与当前pc有着固定的偏移量
- 仅访问嵌入在代码区域中的某些数据
- stack-based指令
- 几乎都是16位编码
- 转换会显著增加代码大小和性能开销
- 上诉原子验证技术可以确保sp的安全性
性能评估
实验环境
- Arduino-Due开发板
- Cortex-M3处理器
- 将CPU频率降低到18.5MHz,以获得一致的结果(在实验过程中发现,即使处理器中没有缓存,运行的程序也会根据代码的对齐方式给出非常不一致的结果。Arduino-Due处理器核心在默认设置下以84MHz运行时,必须等待4个时钟周期(flash wait state)才能从flash中获得稳定的结果。)
- RIOT-OS
- BEEBS benchmark suite
实验结果
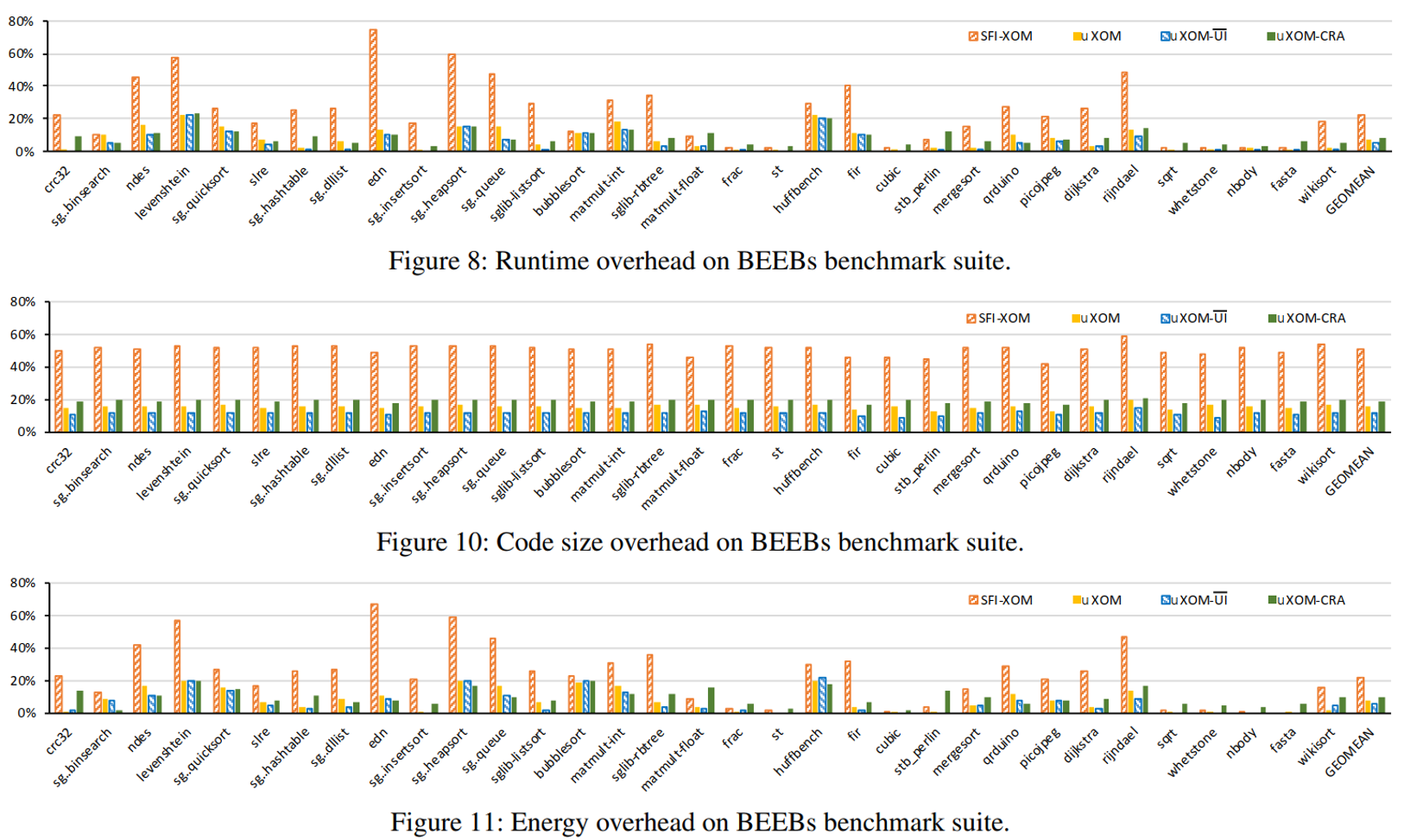 注解:
注解:
SFI-XOM:基于SFI技术实现的XOM,将不可信的模块放在沙箱中运行
uXOM:基于本文设计实现的程序
uXOM-$\overline{UI}$:未处理unintended instruction的uXOM
uXOM-CRA:uXOM的用例,基于Readactor的CRA防御解决方案
运行开销
几何平均:22.7%/SFI-XOM, 7.3%/uXOM, 5.2%/uXOM-$\overline{UI}$, 8.6%/uXOM-CRA
- 由于Cortex-M处理器低功耗和无缓存,基于SFI的XOM的开销相对要大很多
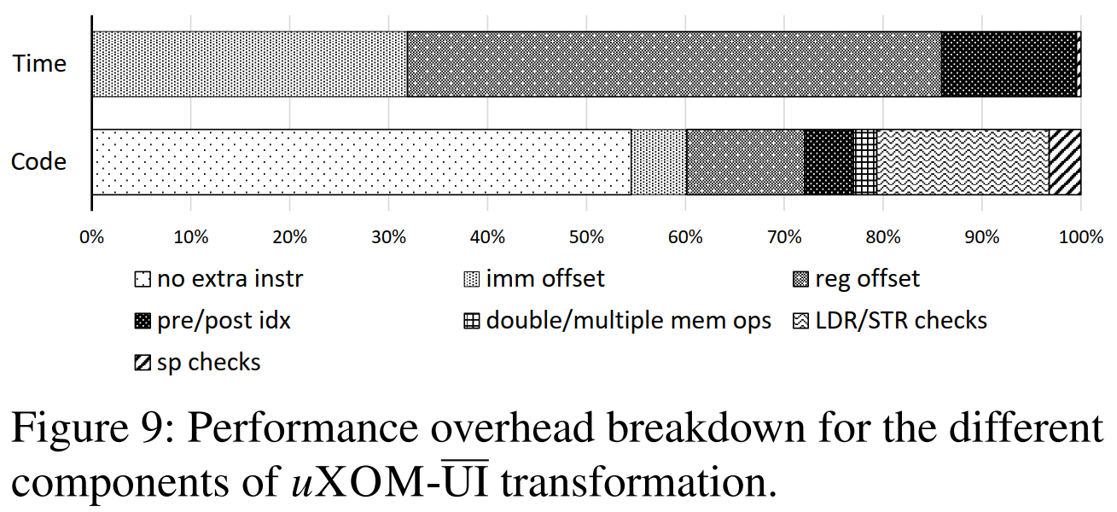
- 通过对比uXOM和uXOM-$\overline{UI}$,除非转换时添加了额外指令,否则非特权内存指令不会增加开销,如下图所示:
代码开销
几何平均:50.8%/SFI-XOM, 15.7%/uXOM, 11.6%/uXOM-$\overline{UI}$, 19.3%/uXOM-CRA
能源开销
几何平均:22.3%/SFI-XOM, 7.5%/uXOM, 5.8%/uXOM-$\overline{UI}$, 9.7%/uXOM-CRA
总结
- 在Cortex-M处理器上利用软件技术和硬件特性实现了XOM
- MPU
- 无特权内存指令
- 强大的威胁模型
- 假设攻击者能够执行任意内存读写,并能够劫持控制流
- 不信任所有固件组件
- 评估结果
- 在性能和安全性方面优于基于SFI的XOM
- 能够防止代码泄露攻击(密钥保护,CRA防御)